# coding:utf-8
import glob # 引用glob #提取行数据 代码位置在哪,data保存到哪 处理时文件不要打开,不然报错。
import numpy as np # 引用numpy
import openpyxl
from openpyxl import load_workbook # 引用openpyxl的load_workbook
flist = glob.glob(r'D:\huangjingdata\meteorology\over\*.txt') # 读取当前文件夹所有txt,并存入列表
wb = load_workbook('G:\\data2py\\2019.xlsx') # 打开要保存数据的excel
sheet = wb['Sheet1'] # 打开要保存数据的sheet
j = 1 # 序数,用来将从txt提取的数据存储(放)到excel的不同行
x = 0
for x in range(23):
for filename in flist: # 利用for循环逐个读取txt文件
array = np.loadtxt(filename, dtype=str, delimiter='\t') # 将当前读取的txt文件数据存储矩阵,定界符为‘\t’
number_col = array.shape[1] # 获取数据矩阵列数
for i in range(number_col):
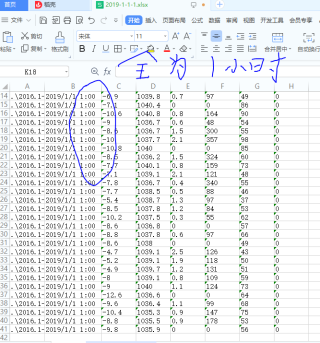
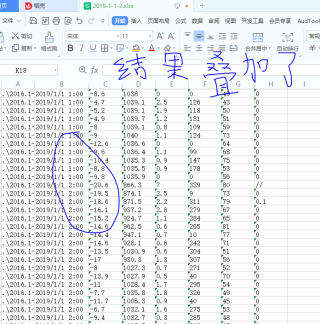
sheet.cell(j, i + 1).value = array[x][i] # 将需要用的第一行数据存储在excel中,就是'sheet1',本次代码为第一行,因为从0开始
j = j + 1 # 行叠加 ,开始第二行 # #行不变,列要变化(i+1)
x = x+1
wb.save("2019-1-1-"+str(x) +'.xlsx') # 保存excel文件并退出