

今天练习一下pychon的爬取,就写了一个爬取三国演义的爬虫,结果在输出中文时出现乱码。
import requests
from bs4 import BeautifulSoup
url='https://www.shicimingju.com/book/sanguoyanyi.html'
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36'
}
page_text=requests.get(url=url,headers=headers).text
soup=BeautifulSoup(page_text,'lxml')
li_list=soup.select('.book-mulu>ul>li')
fp=open('./三国演义.txt','w',encoding='utf-8')
for li in li_list:
title=li.a.string
detail_url='https://www.shicimingju.com/'+li.a['href']
detail_url_text=requests.get(url=detail_url,headers=headers).text
detail_soup=BeautifulSoup(detail_url_text,'lxml')
div_tag=detail_soup.find('div',class_='chapter_content')
content = div_tag.text
fp.write(title+':'+content+'\n')
print(title,'爬取完毕!!!')
print('全部爬取完毕')
爬出来的全是中文乱码:
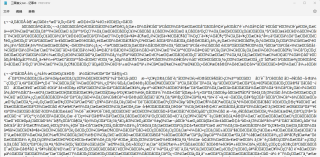
已经加入了encoding='utf-8'后依然如此,上网找百度也寻觅无果,求指点









