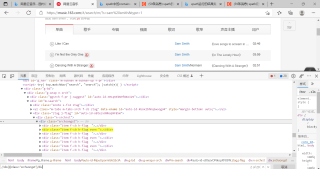
网易云源码内xpath语法://div[@class="srchsongst"]/div可以搜索到20个结果,如下图:
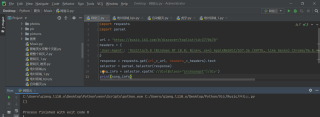
PyCharm中语法及运行结果如下:

网易云源码内xpath语法://div[@class="srchsongst"]/div可以搜索到20个结果,如下图:
PyCharm中语法及运行结果如下:
 分享
分享 系统已结题
1月24日
系统已结题
1月24日 已采纳回答
1月16日
创建了问题
1月16日
已采纳回答
1月16日
创建了问题
1月16日

