scrapy在settdings.py中已经设置好了DEFAULT_REQUEST_HEADERS,在发起请求的时候应该怎么写headers?

scrapy在settdings.py中已经设置好了DEFAULT_REQUEST_HEADERS,在发起请求的时候应该怎么写headers?

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

2条回答 默认 最新


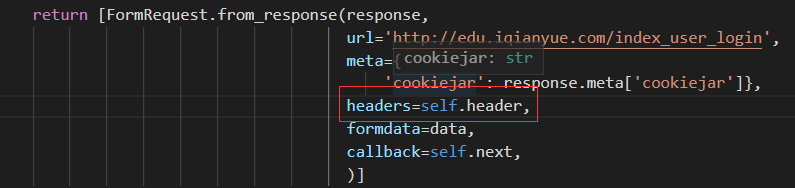
- 2024-12-09 00:57盲敲代码的阿豪的博客 Scrapy框架中的settings.py文件是用于配置爬取相关设置的文件,通过修改该文件可以自定义爬虫的行为。以下是settings.py文件中一些常见参数的详细说明以及使用方法,并附带相关案例。
- 2023-04-17 10:40禾戊之昂的博客 settings.py 文件是 Scrapy框架下,用来进行全局配置的设置文件,可以进行 User-Agent 、请求头、最大并发数等的设置,本文中介绍 settings.py 文件下的一些常用配置
- 2020-09-18 00:28DEFAULT_REQUEST_HEADERS = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', ... } ``` - **描述**: 可以覆盖默认的HTTP头部字段,例如Accept字段等。 以上介绍的命令和...
- 2022-09-04 10:08街 三 仔的博客 settings.py文件中的相关配置说明 USER_AGENT配置 ROBOTSTXT_OBEY 协议 DOWNLOAD_DELAY DOWNLOADER_MIDDLEWARES 下载中间件 ITEM_PIPELINES 管道 COOKIES_ENABLED 配置cookie
- 2025-05-03 16:08不会飞的鲨鱼的博客 文件的主要作用是对Scrapy项目的全局设置进行集中管理。借助修改这个文件中的配置项,你可以对爬虫的行为、性能、数据处理等方面进行灵活调整,而无需修改爬虫代码。
- 2020-12-09 11:28weixin_39797780的博客 本文实例讲述了Scrapy框架基本命令与settings.py设置。分享给大家供大家参考,具体如下:Scrapy框架基本命令1.创建爬虫项目scrapy startproject [项目名称]2.创建爬虫文件scrapy genspider +文件名+网址3.运行(crawl...
- 2024-09-29 16:00栗子~~的博客 请求头相关配置 DEFAULT_REQUEST_HEADERS: 设置默认的请求头,这里通常会设置 User-Agent 和 Accept-Language。这个配置项被注释掉了,说明它使用默认请求头。如果需要自定义,可以启用并设置。 爬虫和下载中间件...
- 2020-04-01 11:42zjLOVEcyj的博客 Scrapy设置(settings)提供了定制Scrapy组件的方法。可以控制包括核心(core),插件(extension),pipeline及spider组件。比如 设置Json Pipeliine、LOG_LEVEL等。 内置设置参考手册 BOT_NAME 默认: ‘scrapybot’ 当...
- 2024-06-12 20:06Adolf_1993的博客 0. 在settings.py中设置。
- 2021-01-28 18:25勃斯李的博客 一、requests设置请求头:import requestsurl="http://www.targetweb.com"headers={'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8','Cache-Control':'max-age=0','...
- 没有解决我的问题, 去提问

