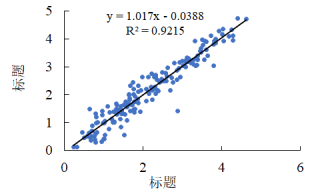
问题遇到的现象和发生背景
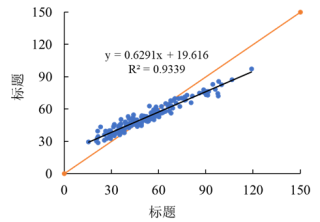
在使用随机森林预测的时候,待评价的有5个指标,其中两个效果好,一个效果一般,两个效果不太好,在检查的过程中发现所有的训练集上
的数据都呈现斜率小于1的趋势,基本上都在0.6左右,我想知道是否有办法可以改善这个问题
问题相关代码,请勿粘贴截图
df_train = pd.read_excel(r'E:\资料\伽马\标定相关性(更新).xlsx', sheet_name='Sheet3')
X = df_train.iloc[:, 3:6].values
Y = df_train.iloc[:, 2:3].values
X = X.astype('float32')
Y = Y.astype('float32')
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.2, random_state=4825)
ss_x = StandardScaler()
x_train = ss_x.fit_transform(x_train)
x_test = ss_x.fit_transform(x_test)
rfr = RandomForestRegressor(random_state=1)
rfr.fit(x_train, y_train.ravel())
rfr_y_predict = rfr.predict(x_test).reshape(-1, 1)
rfr_y_train = rfr.predict(x_train).reshape(-1, 1)
R2_train = r2_score(y_train, rfr_y_train)
RME_train = np.mean(abs((y_train - rfr_y_train) / y_train))#导师要求的评价指标平均相对误差
R2_test = r2_score(y_test, rfr_y_predict)
RME_test = np.mean(abs((y_test - rfr_y_predict) / y_test))#导师要求的评价指标平均相对误差
我想要达到的结果
能够像神经网络得到的结果一样斜率在1左右