
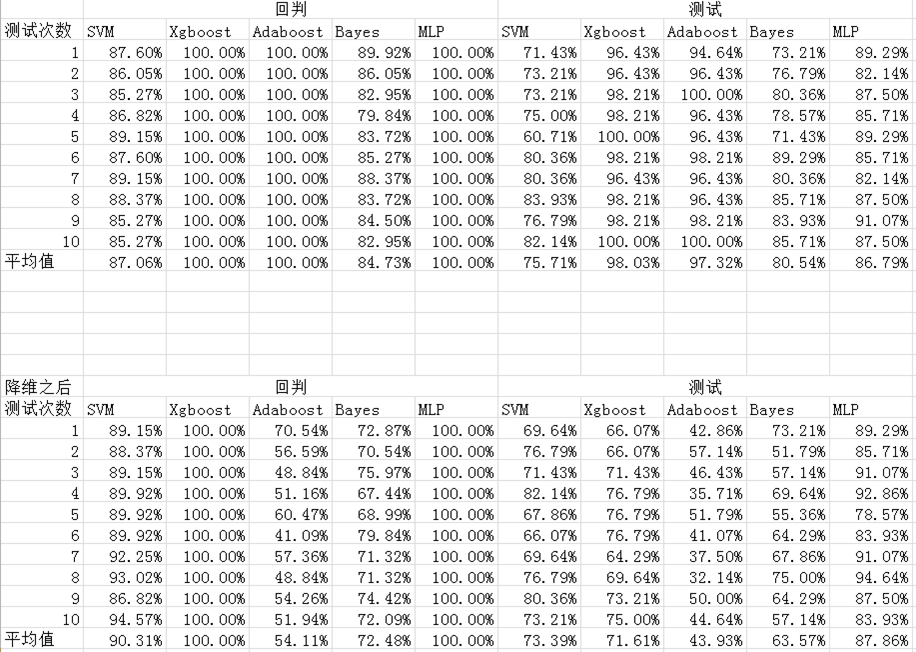
我使用五种方法同时对原始数据和主成分分析PCA处理之后的数据进行分析,并且进行回判和预测,发现SVM和神经网络前后变化不大,但是XGBoost、AdaBoost以及Bayes的成功率反而有所降低,请问是不是因为这几个方法不适合主成分分析降维?

主成分分析降维会影响到机器学习的精度么?

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

2条回答 默认 最新
 threenewbee 2019-07-18 19:27关注
threenewbee 2019-07-18 19:27关注这个和你的数据的关联度有关。做了PCA降维以后,那些关联性比较小的被你剔除了,它们或多或少包含了一些信息也就丢失了。那么或多或少会影响精度。
但是从另外一个角度看,如果你的计算规模大幅缩小,那么你机器学习的效率就提高了,在给定的有限时间和成本上,学习效率提高,你反倒可以得到更好的效果。打一个比方,我们要挖金子,你说是先探明哪里有矿再挖掘,找到的金子多,还是漫无目的挖掘找的多?这个问题得这么看:
如果你有无限多的时间、不计成本,你不管哪里有矿没矿,把整个地球全部挖一遍,肯定得到的金子最多,因为即便不是矿的地方,多少也能挖一点点非常微量的金子,甚至海水中都溶解着金子。
但是现实中,我们不是有无穷多的矿工,无穷多的时间,那么先找到哪里有矿,在矿场挖,在给定的成本里,肯定比随便挖挖到的金子多。本回答被题主选为最佳回答 , 对您是否有帮助呢?评论 打赏解决 5无用举报 分享
- 2024-10-31 17:46西柚小萌新吖(●ˇ∀ˇ●)的博客 降维的主要方法: 机器学习中数据降维的方法又很多: 主成分分析(Principal Component Analysis) 等距映射(Isometric Mapping) 局部线性嵌入(Locally Linear Embedding) …… 主要可以分为特征选择和特征抽取...
- 2023-03-05 22:29Lies.的博客 PCA(Principal Component Analysis),即主成分分析方法,是一种使用最广泛的数据降维算法。PCA的主要思想是将n维特征映射到k维上,这k维是全新的正交特征也被称为主成分,是在原有n维特征的基础上重新构造出来的k维...
- 2020-04-22 17:33爱学习的老青年的博客 PCA(Principal Component Analysis),即主成分分析方法,是一种使用最广泛的数据降维算法(非监督的机器学习方法)。 其最主要的用途在于“降维”,通过析取主成分显出的最大的个别差异,发现更便于人类理解的特征。...
- 2024-06-16 10:52ohoh。的博客 主成分分析(Principal Component Analysis, 简称PCA)是一种常见的统计方法,用于数据降维和特征提取。它通过线性变换将原始数据投影到一个由各主成分组成的新坐标系中,这些主成分是原始数据中方差最大的方向。...
- 2025-06-06 23:432302_81076207的博客 PCA 是一种无监督线性降维方法,它将原始高维特征空间的数据,通过线性变换映射到低维空间,新的维度(主成分)是原始特征的线性组合,且各主成分间正交(互不相关),按对数据方差的解释能力排序,第一主成分方差...
- 2025-06-03 19:34Ao000000的博客 主成分分析(Principal Component Analysis,PCA)是一种常用的数据降维方法。它通过线性变换将原始数据变换到一个新的坐标系中,使得第一个坐标(第一主成分)具有最大的方差,第二个坐标(第二主成分)具有次大的...
- 2024-01-01 00:40秋汐657的博客 主成分分析是一种强大的数据降维技术,可以帮助提取数据的主要特征并消除相关性,有助于提高模型的准确性和可解释性。
- 2023-12-30 21:13衍浒的博客 它最早由卡尔·皮尔逊于1901年提出,是一种统计学方法,后来被广泛引入到机器学习领域。主成分分析的背景和意义主要体现在以下几个方面:1.数据降维:在现实世界中,许多数据集具有高维特征,这给数据的存储、可视化...
- 2025-06-03 20:07闻人翊悬.519的博客 主成分分析(Principal Component Analysis,PCA) 是一种常用的降维技术,属于无监督方法,用于将高维数据转换为低维表示,同时尽可能保留原始数据的关键信息。通过线性变换,将原始高维向量通过投影矩阵,投射到低维...
- 2024-03-19 08:54不二人生的博客 主成分分析(PCA) 技术由数学家于 1901 年提出它的工作前提是,当高维空间中的数据映射到低维空间中的数据时,低维空间中的数据的方差应该是最大的。**主成分分析 (PCA)**是一种统计过程,它使用正交变换将一组相关...
- 没有解决我的问题, 去提问
