
论文中给的频域图(DCT)是这样的:

公式1如下:
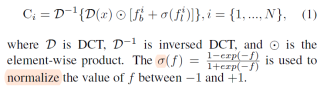
但我用作者给的代码,生成的图像是这样的:

请问,我要做什么处理,才能变成作者那样的?
作者提供的核心代码如下:
import numpy as np
import torch
from torch import nn
from PIL import Image
import torchvision.transforms.functional as F
import torchvision.utils as vutils
class Filter(nn.Module):
def __init__(self, size, band_start, band_end, use_learnable=True, norm=False):
super(Filter, self).__init__()
self.use_learnable = use_learnable
self.base = nn.Parameter(torch.tensor(generate_filter(band_start, band_end, size)), requires_grad=False)
if self.use_learnable:
# 根据size为每一个坐标位置随机生成数字
self.learnable = nn.Parameter(torch.randn(size, size), requires_grad=True)
self.learnable.data.normal_(0., 0.1)
# Todo
# self.learnable = nn.Parameter(torch.rand((size, size)) * 0.2 - 0.1, requires_grad=True)
self.norm = norm
if norm:
self.ft_num = nn.Parameter(torch.sum(torch.tensor(generate_filter(band_start, band_end, size))), requires_grad=False)
def forward(self, x):
if self.use_learnable:
filt = self.base + norm_sigma(self.learnable)
else:
filt = self.base
if self.norm:
y = x * filt / self.ft_num
else:
y = x * filt
return y
# 根据图像的尺寸生成傅里叶矩阵
def DCT_mat(size):
m = [[ (np.sqrt(1./size) if i == 0 else np.sqrt(2./size)) * np.cos((j + 0.5) * np.pi * i / size) for j in range(size)] for i in range(size)]
return m
# 尺寸范围内设1,否则设0
def generate_filter(start, end, size):
return [[0. if i + j > end or i + j <= start else 1. for j in range(size)] for i in range(size)]
# 将值归一化为-1~1
def norm_sigma(x):
return 2. * torch.sigmoid(x) - 1.
class FAD_Head(nn.Module):
def __init__(self, size):
super(FAD_Head, self).__init__()
# init DCT matrix
# 生成傅里叶矩阵
self._DCT_all = nn.Parameter(torch.tensor(DCT_mat(size)).float(), requires_grad=False)
# 傅里叶矩阵转置
self._DCT_all_T = nn.Parameter(torch.transpose(torch.tensor(DCT_mat(size)).float(), 0, 1), requires_grad=False)
# define base filters and learnable
# 0 - 1/16 || 1/16 - 1/8 || 1/8 - 1 || 0 - 1
low_filter = Filter(size, 0, size // 16)
middle_filter = Filter(size, size // 16, size // 8)
high_filter = Filter(size, size // 8, size)
all_filter = Filter(size, 0, size)
self.filters = nn.ModuleList([low_filter, middle_filter, high_filter, all_filter])
def forward(self, x):
# DCT 对应论文中公式1
x_freq = self._DCT_all @ x @ self._DCT_all_T # [N, 3, 224, 224]
vutils.save_image(x_freq, "rgb_freq.png")
# 4 kernel
y_list = []
for i in range(4):
x_pass = self.filters[i](x_freq) # [N, 3, 224, 224]
y = self._DCT_all_T @ x_pass @ self._DCT_all # [N, 3, 224, 224]
vutils.save_image(y[:,:,:], f"rgb_freq_{i}.png")
y_list.append(y)
# 拼接四个可学习的频域图
out = torch.cat(y_list, dim=1) # [N, 12, 224, 224]
return out
if __name__ == '__main__':
img_path = "2.png"
rgb = Image.open(img_path).convert("RGB")
rgb = F.to_tensor(rgb)
freq = FAD_Head(size=256)
rgb_freq = freq(rgb)
测试图像:

2.png
PS:谁能帮我用代码解决这个问题,赏金就归谁(按时间顺序的第一个人),谢谢大家!








