服务器自带的显卡驱动和cuda要怎么删掉啊?我看好多教程都是要用unistall,但是我这文件夹下面,根本就没有这个文件,要怎么弄啊?

服务器自带的显卡驱动和cuda要怎么删掉啊?我看好多教程都是要用unistall,但是我这文件夹下面,根本就没有这个文件,要怎么弄啊?
 分享
分享
 关注
关注【相关推荐】
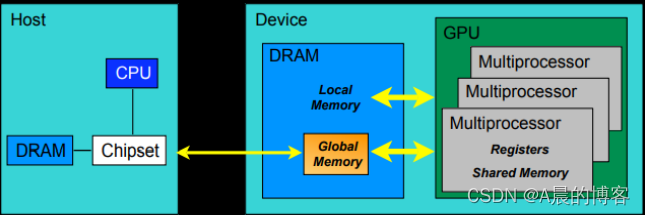
下图为GPU硬件模型:
一块GPU包括3级:GPU、多核处理器、线程处理器
在CUDA编程时,我们经常用到thread, block, grid,其中thread对应硬件上的线程处理器,grid对应一块GPU。而block可以由我们自定义维度,对应到硬件上,其实是由一个多核处理器中的多个线程处理器组合而成,可以将一个多核处理器划分为多个block。
线程束(warp)是最基本的执行单元,一个warp包含32个基本的计算单元-线程thread,也就是说比如我发一个指令,那么线程束中的32个thread将会并行执行该指令。(所以在我们划分blocksize的时候,一般都会设置成32的倍数)

分享 创建了问题
1月19日
创建了问题
1月19日



