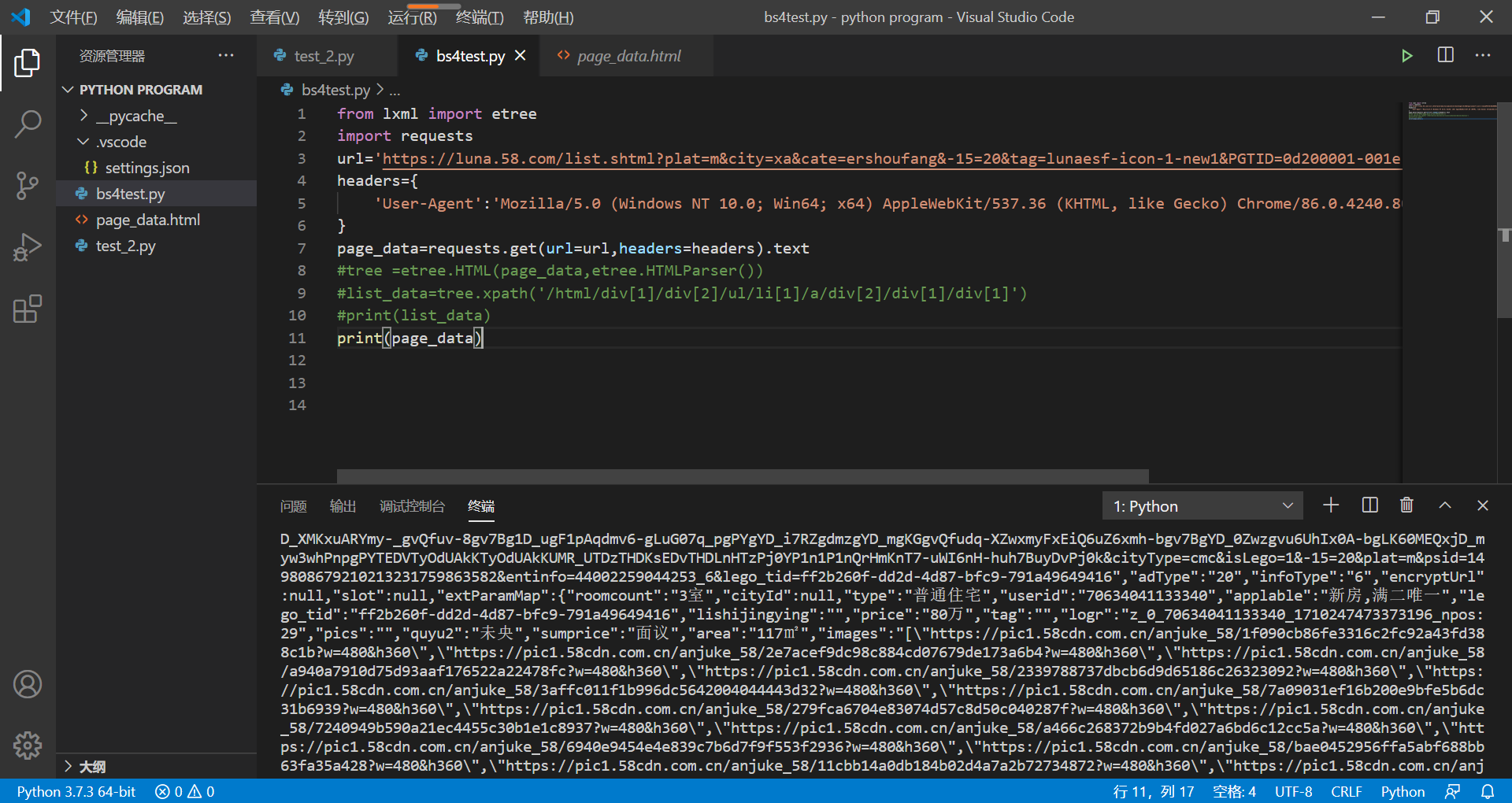
今天尝试用xpath去解析响应数据的时候,发现无论怎么调,都是返回空列表,获取的页面源码也是正确的,xpath路径是自己写的,在开发者工具中也能定位到确定的位置,可是从代码中
输出就是空列表?为什么?
from lxml import etree
import requests
url='https://luna.58.com/list.shtml?plat=m&city=xa&cate=ershoufang&-15=20&tag=lunaesf-icon-1-new1&PGTID=0d200001-001e-3bee-3ddb-ca3c7f0c2292&ClickID=2'
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.80 Safari/537.36 Edg/86.0.622.48'
}
page_data=requests.get(url=url,headers=headers).text
tree =etree.HTML(page_data,etree.HTMLParser())
list_data=tree.xpath('/html/div[1]/div[2]/ul/li[1]/a/div[2]/div[1]/div[1]')
print(list_data)