
我用的是mac,用的python版本是3.6。想要爬取政府网站上的一些信息,然而出来的都是乱码,如图:
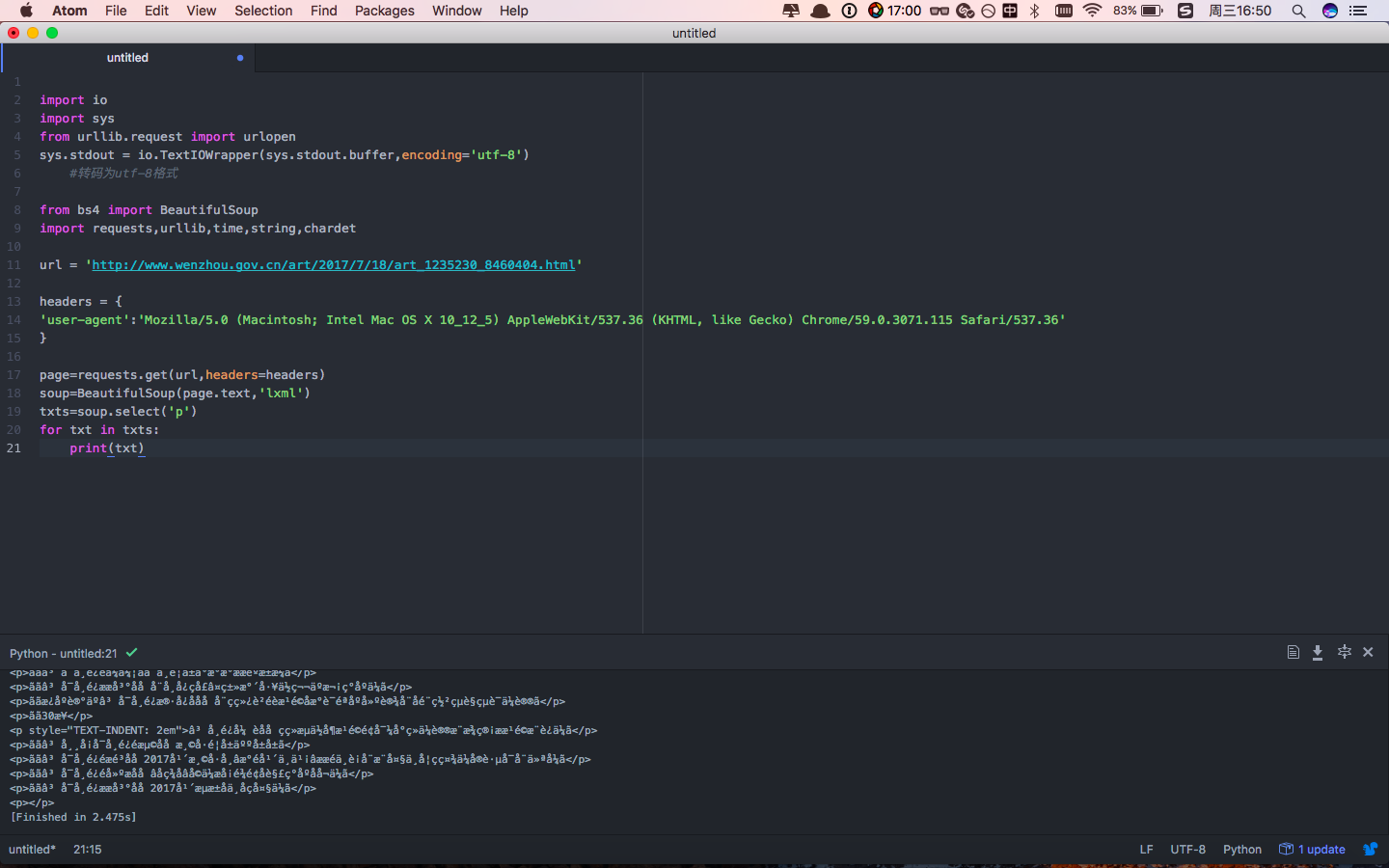
下面是我的代码:
import io
import sys
from urllib.request import urlopen
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf-8')
#转码为utf-8格式
from bs4 import BeautifulSoup
import requests,urllib,time,string,chardet
url = 'http://www.wenzhou.gov.cn/art/2017/7/18/art_1235230_8460404.html'
headers = {
'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'
}
page=requests.get(url,headers=headers)
soup=BeautifulSoup(page.text,'lxml')
txts=soup.select('p')
for txt in txts:
print(txt)
请各位大神指导!





