def train(mnist):
x = tf.placeholder(tf.float32, [None, INPUT_NODE], name='x-input')
y_ = tf.placeholder(tf.float32, [None, OUTPUT_NODE], name='y-input')
weights1 = tf.Variable(
tf.truncated_normal([INPUT_NODE, LAYER1_NODE], stddev=0.1))
biases1 = tf.Variable(tf.constant(0.1, shape=[LAYER1_NODE]))
weights2 = tf.Variable(
tf.truncated_normal([LAYER1_NODE, OUTPUT_NODE], stddev=0.1))
biases2 = tf.Variable(tf.constant(0.1, shape=[OUTPUT_NODE]))
#计算向前传播y的输出值,此处首次向前传播计算,不必使用滑动平均值来进行权值优化,固填为None
y = inference(x, None, weights1, biases1, weights2, biases2)
#存储训练轮数,变量为不可训练的变量
global_step = tf.Variable(0, trainable=False)
#给定滑动平均衰减率和训练轮数的变量,初始化滑动平均类,给定训练轮数可以加快早期
#变量训练速度
variable_averages = tf.train.ExponentialMovingAverage(
MOVING_AVERAGE_DECAY, global_step) #创建指数移动平均类
#在所有代表神经网络参数的变量上使用滑动平均,这个集合元素是所有没有指定
#trainable = False 的参数
variable_averages_op = variable_averages.apply(
tf.trainable_variables()) #将上类作用于当前所有可训练变量
#计算使用滑动平均的Y值,这里调用之前定义的inference函数,获取参数
average_y = inference(x, variable_averages, weights1, biases1, weights2, biases2)
#计算交叉熵,作为刻画真实值y与预测值y_之间的差距
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(
logits=y, labels=tf.argmax(y_, 1))
#计算当前BATCH中所有样例的交叉熵平均值
corss_entropy_mean = tf.reduce_mean(cross_entropy)
#计算L2正则化损失函数
regularizer = tf.contrib.layers.l2_regularizer(REGULARIZATION_RATE)
#计算模型正则化损失
regularization = regularizer(weights1) + regularizer(weights2)
#总损失为交叉熵与正则化的和
loss = cross_entropy_mean + regularization
#衰减学习率
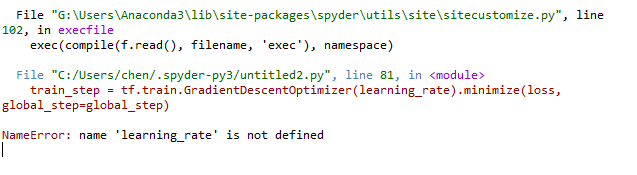
global learning_rate
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE, global_step, mnist.train.num_examples / BATCH_SIZE, LEARNING_RATE_DECAY)
#最小化loss
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
with tf.control_dependencies([train_step, Variables_averages_op]):
train_op = tf.no_op(name='train')
可以看到在前面的train函数中定义了learning_rate局部变量,但是在外部调用时出现变量未定义的报错,我定义全局变量也没有用