
def loss(self,X,y,reg):
loss = 0.0
dW = np.zeros_like(self.W)
num_train = X.shape[0]
num_class = self.W.shape[1]
one_hot = np.zeros(shape = (num_train,num_class))
y = y.astype('int64')
one_hot[np.arange(0,num_train), y] = 1
Z = X.dot(self.W)
Z_max = np.max(Z,axis = 1,keepdims = True) #Z_max = Z.max(1).reshape(num_train,1)
Z = Z - Z_max #max(1) get the maxmum of each row
score_E = np.exp(Z)
Sum = np.sum(score_E,axis = 1,keepdims = True)#score_E.sum(axis = 1).reshape(num_train,1) # sum of each row
A = score_E/Sum #score of every class of each training_example
A1 = np.where(A > 0.0000000001, A, 0.0000000001)
loss += -np.sum(one_hot*np.log(A1))/num_train + 0.5 * reg * np.sum(self.W * self.W)
dW += -np.dot(X.T, one_hot - A) / num_train + reg * self.W
return loss,dW
以上是我用python写的softmax的损失函数部分,但是在运行过程中发现输出里有时仍有这样的情况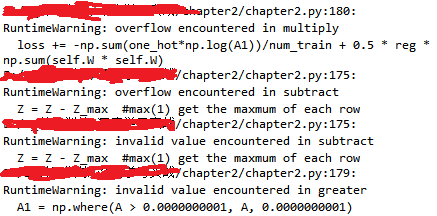
我只对图片做了零均值化,没有归一化,但是Z = Z - Z_max 溢出就说不通啊,这是怎么回事,有没有大神解释??





