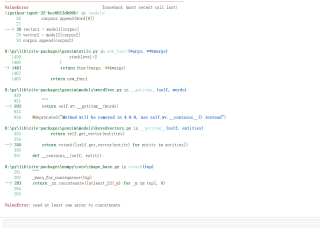
加载训练模型后,调用就报错,请问怎么解决急
from gensim.models import Word2Vec
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
KM = KMeans(n_clusters=2)
model1 = Word2Vec.load("chinese_model.model") #加载训练好的模型
corpus = []
corpus2= []
corpusx= []
B = model1.wv.index2word #获取word2vec训练过的词汇
gb = open('chinese',encoding='utf-8').readlines()
for word in gb[:30]: #为了方便,每个词库只取了前面30个单词
word = word.split('\n')
if word[0] in B:
corpus.append(word[0])
corpusx.append(word[0])
model2 = Word2Vec.load("english_model") #加载训练好的模型
B = model2.wv.index2word
fb = open('english').readlines()
for word in fb[:30]:
word = word.split('\n')
if word[0] in B:
corpus2.append(word[0])
corpusx.append(word[0])
vector1 = model1[corpus]
vector2 = model2[corpus2]
corpus.append(corpus2)
print(corpusx)
#vecter=vector1+vector2