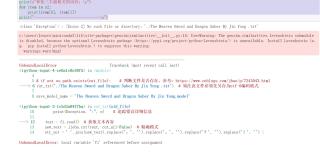
jupyter notebook运行代码找不到txt语料库文件
# 此函数作用是对初始语料进行分词处理后,作为训练模型的语料
def cut_txt(old_file):
import jieba
global cut_file # 分词之后保存的文件名
cut_file = old_file + '_cut.txt'
try:
fi = open(old_file, 'r', encoding='utf-8')
except BaseException as e: # 因BaseException是所有错误的基类,用它可以获得所有错误类型
print(Exception, ":", e) # 追踪错误详细信息
text = fi.read() # 获取文本内容
new_text = jieba.cut(text, cut_all=False) # 精确模式
str_out = ' '.join(new_text).replace(',', '').replace('。', '').replace('?', '').replace('!', '') \
.replace('“', '').replace('”', '').replace(':', '').replace('…', '').replace('(', '').replace(')', '') \
.replace('—', '').replace('《', '').replace('》', '').replace('、', '').replace('‘', '') \
.replace('’', '') # 去掉标点符号
fo = open(cut_file, 'w', encoding='utf-8')
fo.write(str_out)
def model_train(train_file_name, save_model_file): # model_file_name为训练语料的路径,save_model为保存模型名
from gensim.models import word2vec
import gensim
import logging
# 模型训练,生成词向量
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
sentences = word2vec.Text8Corpus(train_file_name) # 加载语料
model = gensim.models.Word2Vec(sentences, size=200) # 训练skip-gram模型; 默认window=5
model.save(save_model_file)
model.wv.save_word2vec_format(save_model_name + ".bin", binary=True) # 以二进制类型保存模型以便重用
#下一模块
from gensim.models import word2vec
import os
import gensim
# if not os.path.exists(cut_file): # 判断文件是否存在,参考:https://www.cnblogs.com/jhao/p/7243043.html
cut_txt('./The Heaven Sword and Dragon Saber By Jin Yong .txt') # 须注意文件必须先另存为utf-8编码格式
save_model_name = 'The Heaven Sword and Dragon Saber By Jin Yong.model'
if not os.path.exists(save_model_name): # 判断文件是否存在
model_train(cut_file, save_model_name)
else:
print('此训练模型已经存在,不用再次训练')
# 加载已训练好的模型
model_1 = word2vec.Word2Vec.load(save_model_name)
# 计算两个词的相似度/相关程度
y1 = model_1.similarity("赵敏", "韦一笑")
print(u"赵敏和韦一笑的相似度为:", y1)
print("-------------------------------\n")
# 计算某个词的相关词列表
y2 = model_1.most_similar("张三丰", topn=10) # 10个最相关的
print(u"和张三丰最相关的词有:\n")
for item in y2:
print(item[0], item[1])
print("-------------------------------\n")