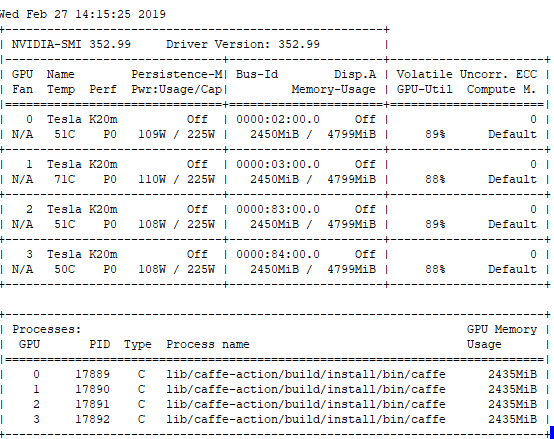
报错信息:
I0227 13:57:10.174791 17889 solver.cpp:365] Model Synchronization Communication time 0.071111 second
I0227 13:57:10.275547 17889 solver.cpp:365] Model Synchronization Communication time 0.0634275 second
I0227 13:57:10.275617 17889 solver.cpp:456] Iteration 0, Testing net (#0)
I0227 13:57:11.660853 17889 cudnn_conv_layer.cpp:186] Optimized cudnn conv
I0227 14:18:10.495625 17889 solver.cpp:513] Test net output #0: accuracy_top1 = 0.857785
I0227 14:18:10.495926 17889 solver.cpp:513] Test net output #1: accuracy_top1_motion = 0.0103093
I0227 14:18:10.495939 17889 solver.cpp:513] Test net output #2: accuracy_top1_motion_14 = 0.0103093
I0227 14:18:10.495947 17889 solver.cpp:513] Test net output #3: accuracy_top1_motion_28 = 0.010838
I0227 14:18:10.495954 17889 solver.cpp:513] Test net output #4: accuracy_top1_motion_fusion = 0.856992
I0227 14:18:10.495965 17889 solver.cpp:513] Test net output #5: loss = 4.6683 (* 1 = 4.6683 loss)
I0227 14:18:10.495975 17889 solver.cpp:513] Test net output #6: loss_14 = 4.6196 (* 1 = 4.6196 loss)
I0227 14:18:10.495985 17889 solver.cpp:513] Test net output #7: loss_28 = 4.62227 (* 1 = 4.62227 loss)
F0227 14:18:11.252009 17892 syncedmem.cpp:51] Check failed: error == cudaSuccess (2 vs. 0) out of memory
*** Check failure stack trace: ***
F0227 14:18:11.252311 17889 syncedmem.cpp:51] Check failed: error == cudaSuccess (2 vs. 0) out of memory
*** Check failure stack trace: ***
@ 0x7fd2deed9dbd google::LogMessage::Fail()
@ 0x7f70d80dddbd google::LogMessage::Fail()
F0227 14:18:11.254006 17891 syncedmem.cpp:51] Check failed: error == cudaSuccess (2 vs. 0) out of memory
*** Check failure stack trace: ***
@ 0x7fd2deedbcf8 google::LogMessage::SendToLog()
@ 0x7f70d80dfcf8 google::LogMessage::SendToLog()
F0227 14:18:11.254802 17890 syncedmem.cpp:51] Check failed: error == cudaSuccess (2 vs. 0) out of memory
*** Check failure stack trace: ***
@ 0x7f766019fdbd google::LogMessage::Fail()
@ 0x7fd2deed9953 google::LogMessage::Flush()
@ 0x7f70d80dd953 google::LogMessage::Flush()
@ 0x7f714c5cedbd google::LogMessage::Fail()
@ 0x7f76601a1cf8 google::LogMessage::SendToLog()
@ 0x7fd2deedc62e google::LogMessageFatal::~LogMessageFatal()
@ 0x7f70d80e062e google::LogMessageFatal::~LogMessageFatal()
@ 0x7f714c5d0cf8 google::LogMessage::SendToLog()
@ 0x7f766019f953 google::LogMessage::Flush()
@ 0x7fd2df2aaa6a caffe::SyncedMemory::mutable_gpu_data()
@ 0x7f70d84aea6a caffe::SyncedMemory::mutable_gpu_data()
@ 0x7f714c5ce953 google::LogMessage::Flush()
@ 0x7f76601a262e google::LogMessageFatal::~LogMessageFatal()
@ 0x7fd2df3cc9f2 caffe::Blob<>::mutable_gpu_data()
@ 0x7f70d85d09f2 caffe::Blob<>::mutable_gpu_data()
@ 0x7f714c5d162e google::LogMessageFatal::~LogMessageFatal()
@ 0x7f7660570a6a caffe::SyncedMemory::mutable_gpu_data()
@ 0x7fd2df423c84 caffe::BNLayer<>::Backward_gpu()
@ 0x7f70d8627c84 caffe::BNLayer<>::Backward_gpu()
@ 0x7f714c99fa6a caffe::SyncedMemory::mutable_gpu_data()
@ 0x7f76606929f2 caffe::Blob<>::mutable_gpu_data()
@ 0x7fd2df3f2905 caffe::CuDNNBNLayer<>::Backward_gpu()
@ 0x7f70d85f6905 caffe::CuDNNBNLayer<>::Backward_gpu()
@ 0x7f714cac19f2 caffe::Blob<>::mutable_gpu_data()
@ 0x7f76606e9c84 caffe::BNLayer<>::Backward_gpu()
@ 0x7fd2df236ad6 caffe::Net<>::BackwardFromTo()
@ 0x7f70d843aad6 caffe::Net<>::BackwardFromTo()
@ 0x7f714cb18c84 caffe::BNLayer<>::Backward_gpu()
@ 0x7f76606b8905 caffe::CuDNNBNLayer<>::Backward_gpu()
@ 0x7fd2df236d71 caffe::Net<>::Backward()
@ 0x7f70d843ad71 caffe::Net<>::Backward()
@ 0x7f714cae7905 caffe::CuDNNBNLayer<>::Backward_gpu()
@ 0x7f76604fcad6 caffe::Net<>::BackwardFromTo()
@ 0x7fd2df3c7bdf caffe::Solver<>::Step()
@ 0x7f70d85cbbdf caffe::Solver<>::Step()
@ 0x7f714c92bad6 caffe::Net<>::BackwardFromTo()
@ 0x7f76604fcd71 caffe::Net<>::Backward()
@ 0x7fd2df3c8408 caffe::Solver<>::Solve()
@ 0x408e76 train()
@ 0x407386 main
@ 0x7f70d85cc408 caffe::Solver<>::Solve()
@ 0x408e76 train()
@ 0x407386 main
@ 0x7f714c92bd71 caffe::Net<>::Backward()
@ 0x7f766068dbdf caffe::Solver<>::Step()
@ 0x7fd2de10cf45 __libc_start_main
@ 0x40793d (unknown)
@ 0x7f70d7310f45 __libc_start_main
@ 0x40793d (unknown)
@ 0x7f714cabcbdf caffe::Solver<>::Step()
@ 0x7f766068e408 caffe::Solver<>::Solve()
@ 0x408e76 train()
@ 0x407386 main
@ 0x7f714cabd408 caffe::Solver<>::Solve()
@ 0x408e76 train()
@ 0x407386 main
@ 0x7f765f3d2f45 __libc_start_main
@ 0x40793d (unknown)
@ 0x7f714b801f45 __libc_start_main
@ 0x40793d (unknown)
--------------------------------------------------------------------------
mpirun noticed that process rank 0 with PID 0 on node s2 exited on signal 6 (Aborted).
--------------------------------------------------------------------------
资源使用情况: