哪位能帮帮我
问题:针对如下数据给出决策树预测。真的搞不懂希望有人能帮帮我
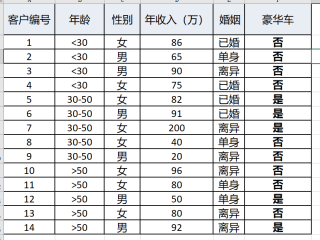

哪位能帮帮我
问题:针对如下数据给出决策树预测。真的搞不懂希望有人能帮帮我
 分享
分享
你需要对字符型变量进行离散编码,如年龄中的“<30”编码为“1”,“30-50”为“2”,“>50”为“3”,其他特征类似,因为如果不编码的话,将这些内容放入Python中的决策树里是识别不了的,因此需要对字符型变量进行编码。编码处理完成可调用sklearn模块中的决策树模型,先进行训练,训练完成可用于预测。
编码处理(可以使用Python处理):
年龄:<30:1,30-50:2,>50:3
性别:女:0,男:1
婚姻:单身:0,已婚:1,离异:2
豪华车:是-1,否-0
import pandas as pd
import numpy as np
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
#数据导入
data = pd.read_csv('data.csv',encoding='gbk')
#分离特征与预测变量
X = data.iloc[:,0:4]
y = data.iloc[:,4]
#随机划分训练集和测试集,
#训练集用于训练模型,使模型具有预测该类数据的能力
#测试集用于测试模型的预测能力如何,并使用指标进行评价
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.3,random_state=7)
#定义决策树模型
model = DecisionTreeClassifier()
#使用训练集训练模型
model.fit(x_train, y_train)
#使用测试集预测并进行评估
y_pred = model.predict(x_test)
print("预测x_test的结果:",y_pred)
print("模型在测试集上的准确率为:",accuracy_score(y_pred, y_test))
#此时调用model.predict()进行预测
pred = model.predict(X)
print("数据集X的预测结果为:",pred)
print("数据集X的真实结果为:",np.array(y))
 已结题
(查看结题原因) 4月23日
已采纳回答
4月23日
创建了问题
4月22日
已结题
(查看结题原因) 4月23日
已采纳回答
4月23日
创建了问题
4月22日


