
问题遇到的现象和发生背景
R语言LightGBM包进行多分类,使用的是tif数据,但是得到的结果非常差,原先使用python实现的时候得到的准确度很正常,R中也不知道是什么原因导致的这种现象。我是先随机选取60个区块的数据当做初始数据集,然后进行训练预测,将准确度最低的5个区数据重新加入到训练数据集中,然后再次训练,直至迭代完成。我原先在python中使用相同数据进行相同学习器进行训练,得到的结果并不相同。
问题相关代码,请勿粘贴截图
但是训练出的模型不管是用于训练集还是测试集,得到的预测结果都非常低,不管尝试多少次都只有20%一下:
library(raster)
library(sampling)
library(stringr)
library(lightgbm)
library(dplyr)
library(base)
library(tiff)
library(paradox)
library(mlr3extralearners)
library(mlr3verse)
library(mlr3tuning)
# 读取选取tif
readtif_vector <- function(x){
# 将读取到的tif转化为向量
label <- raster(x)
label = as.matrix(label)
label <- as.vector(t(label))
return(label)
}
readfeature <- function(pathDir,sample){
path = pathDir
i = j = 1
tif = matrix(ncol = 16, nrow = 1)
while(i <= length(sample[[1]])){
data = matrix(ncol = 1,nrow = 1476)
pathsampel = paste(path, sample[[1]][i], sep = '\\')
while(j <= 15){
path_i = dir(pathsampel)
k = readtif_vector(paste(pathsampel, path_i[j], sep = '\\'))
data = cbind(data,k)
j = j + 1
}
j = 1
i = i + 1
tif = rbind(tif,data)
}
tif <- tif[-1,-1]
colnames(tif) <- c(1:15)
return(tif)
}
readlabel <- function(pathDir, sample){
path = pathDir
tif = matrix(ncol = 2, nrow = 1)
i = j = 1
while(i <= length(sample[[1]])) {
data = matrix(ncol = 1,nrow = 1476)
while(j <= length(dir(path))){
if(paste('dilei',sample[[1]][i],'.tif',sep='')==dir(path)[j]){
k = readtif_vector(paste(path,dir(path)[j],sep = '\\'))
data = cbind(data,k)
}
j = j + 1
}
j = 1
i = i + 1
tif = rbind(tif, data)
}
tif <- tif[-1,-1]
return(tif)
}
readtestfeature <- function(pathDir){
getfeaturetestname = list.files(pathDir, pattern = "*.tif$", full.names = TRUE)
tif = matrix(nrow=165312,ncol=1)
i = 1
while(i <= length(getfeaturetestname)){
k = readtif_vector(getfeaturetestname[i])
tif = cbind(tif, k)
i = i + 1
}
tif = tif[,-1]
colnames(tif) <- c(1:15)
return(tif)
}
# 保存图像tif
orginal_param <- raster('D:\\Personality\\paper\\GBDT\\label\\dilei.tif')
save_tif <- function(preds, iteration){
t <- matrix(preds$response,nrow = 252,ncol=656,byrow = TRUE) %>% as.numeric()
t2<-raster(ncol = 252, nrow = 656,
resolution = c(0.0007515805, 0.0007515805),
ext = extent(orginal_param), vals = t)
output = paste('D:\\Personality\\paper\\GBDT\\R\\',iteration,'.tif')
writeRaster(t2,output,overwrite = TRUE)
}
# 概率选区
probability_block <- function(lgb.pred){
n = 41 * 36
i = 1
result = c()
test <- as.matrix(y_test,ncol=1)
while(i <= 165312){
k = i+n-1
a <- test[c(i:k),1] == lgb.pred[i:k]
cnt1 <- sum(a[a=TRUE])
acc <- cnt1/165312
result = c(result,acc)
i = i+n
}
result = result[-sample_block[[3]]]
num = order(result,decreasing=T)[1:5]
list = list()
list[[3]] = c(sample_block[[3]],num)
list[[1]] = orginal_block_name[list[[3]]]
list[[2]] = orginal_block_name[-list[[3]]]
return(list)
}
# 初始数据集创建
orginal_block_name = c()
for(i in 0:6){
for(j in 0:15){
k = paste(i,j,sep='_')
orginal_block_name = c(orginal_block_name,k)
}
}
sampleblock <- function(x){
#随机选区
path = orginal_block_name # 获取当前目录文件名
s<-srswor(x,112) # 随机获取x个区块
ind<-(1:112)[s!=0]
sample<-path[ind]
path <- path[-ind] # 删除x个随机区块
return(list(sample, path, ind))
} # 随机选区
sample_block = sampleblock(90) # 选取70个
# 测试数据
y_test = readtif_vector('D:\\Personality\\paper\\GBDT\\label\\dilei.tif')
x_test = readtestfeature('D:\\Personality\\paper\\GBDT\\train')
# 迭代
iteration = 1
itera_acc <- list()
while (iteration <= 6) {
# 训练数据集
y_train = readlabel('D:\\Personality\\paper\\GBDT\\testshiyan\\label', sample = sample_block)
x_train = readfeature('D:\\Personality\\paper\\GBDT\\testshiyan\\train', sample = sample_block)
# 随机搜索,使用mlr3包进行调优
dtrain <- cbind(x_train, y_train) %>% data.frame()
dtrain$y_train <- factor(dtrain$y_train)
dtest <- cbind(x_test, y_test) %>% data.frame()
dtest$y_test <- factor(dtest$y_test)
dtrain<-as_task_classif(dtrain,target = "y_train",id="a")
dtest<-as_task_classif(dtest,target = 'y_test',id="b")
learner <- lrn("classif.lightgbm") # 创建学习器
search_space <- ps(learning_rate = p_dbl(lower = 0.001, upper = 0.5),
num_iterations = p_int(lower = 200, upper = 600),
num_leaves = p_int(lower = 10, upper = 60),
max_depth = p_int(lower = -1, upper = 10)
) # 设置搜索空间
resampling <- rsmp("holdout") # 选择重抽样方法
terminator <- trm("evals", n_evals = 10) # 设定何时停止训练
measure <- msr("classif.acc") # 选择评价指标
tuner <- tnr("random_search") # 选择搜索方法
# 搜索
at <- AutoTuner$new(
learner = learner,
resampling = resampling,
search_space = search_space,
measure = measure,
tuner = tuner,
terminator = terminator
)
# 训练模型
at$train(dtrain)
# 预测
preds <- at$predict(dtest)
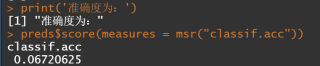
print('-----------------------\n准确度为:')
preds$score(measures = msr("classif.acc"))
print('-----------------------------------')
# 概率选区
sample_block <- probability_block(preds$response)
# tif保存
save_tif(preds,iteration)
iteration = iteration + 1
}
运行结果及报错内容
我的解答思路和尝试过的方法
我尝试使用lightgbm自身的lgb.train进行预测,也尝试使用mlr3的调参后的模型进行预测,但是得到的预测准确度都很低,甚至循环多次后,准确度还降低了。
我想要达到的结果
我想解决这一问题,并能进行正常的模型训练以及预测。







