
现有一个矩阵(tsv文件),行名为ENSG开头+数字编号
前五行五列情况如图
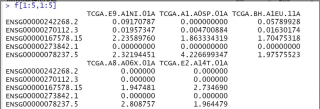
现已知行名中,小数点前数值出现重复,小数点后数值不同,
现需要保留小数点后数值最大的行名,去除其他小数点后数值更小的行名
例如:行名为7700.1 7700.2 7700.5的三行,仅保留7700.5所在行
输出一个行名没有重复的新矩阵,列名不变

现有一个矩阵(tsv文件),行名为ENSG开头+数字编号
前五行五列情况如图
 分享
分享
思路:字符串分割后分组,分组后比较排序后筛选剔除
import pandas as pd
df = pd.read_csv('xxxx.tsv', sep='\t')
df['tempOne'] = df['A'].apply(lambda x: x.split(".")[0])
df['tempTwo'] = df['A'].apply(lambda x: int(x.split(".")[1]))
df_new = df.iloc[df.groupby('tempOne').apply(lambda o: o['tempTwo'].idxmax())]
df_new.drop(['tempOne', 'tempTwo'], axis=1, inplace=True)
源数据:


分享 系统已结题
10月23日
系统已结题
10月23日 已采纳回答
10月15日
创建了问题
10月12日
已采纳回答
10月15日
创建了问题
10月12日


