
RuntimeError: mat1 and mat2 shapes cannot be multiplied (64x64 and 128x64)
近期在调试一个四层的BP神经网络,报出了这样的错误:
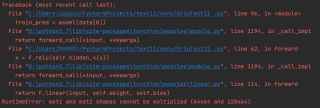
大概知道问题出在这里:
def forward(self, x):
x = F.relu(self.hidden_1(x))
x = self.dropout(self.bn1(x))
x = F.relu(self.hidden_2(x))
x = self.dropout(self.bn2(x))
x = F.relu(self.hidden_3(x))
x = self.dropout(self.bn3(x))
x = F.relu(self.hidden_4(x))%问题所在
x = self.dropout(self.bn4(x))
x = self.out(x)
return x
目前已经尝试过添加
x = torch.flatten(x,1)
不能解决/(ㄒoㄒ)/~~,感觉也不是池化层输出形状的问题叭,因为打印在def forward(self, x)中print(x.shape)输出是([64,64]),唉,神经网络小菜请教如何解决🙇
下面贴出相关代码:
class Classifier(torch.nn.Module):
def __init__(self, n_feature, n_hidden, n_output, dropout=0.5):
super(Classifier, self).__init__()
self.dropout = torch.nn.Dropout(dropout)
self.hidden_1 = torch.nn.Linear(n_feature, n_hidden)
self.bn1 = torch.nn.BatchNorm1d(n_hidden)
self.hidden_2 = torch.nn.Linear(n_hidden, n_hidden//4)
self.bn2 = torch.nn.BatchNorm1d(n_hidden//4)
self.hidden_3 = torch.nn.Linear(n_hidden//4, n_hidden//8)
self.bn3 = torch.nn.BatchNorm1d(n_hidden//8)
#三层卷积与四层卷积
self.hidden_4 = torch.nn.Linear(n_hidden // 4, n_hidden // 8)
self.bn4 = torch.nn.BatchNorm1d(n_hidden // 8)
self.out = torch.nn.Linear(n_hidden//8, n_output)
def forward(self, x):
x = F.relu(self.hidden_1(x))
x = self.dropout(self.bn1(x))
x = F.relu(self.hidden_2(x))
x = self.dropout(self.bn2(x))
x = F.relu(self.hidden_3(x))
x = self.dropout(self.bn3(x))
x = F.relu(self.hidden_4(x))
x = self.dropout(self.bn4(x))
x = self.out(x)
return x
for i, data in enumerate(train_loader):
optimizer.zero_grad()
train_pred = model(data[0])
batch_loss = loss(train_pred, data[1])
batch_loss.backward()
optimizer.step()
train_acc += np.sum(np.argmax(train_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
train_loss += batch_loss.item()







