
#求帮助#如何利用kmeans或kshape聚类分析对归一化的无量纲时间-降雨序列进行聚类(分类,区分降雨雨型的差异),主要需要相关的代码最好是python代码(jupter notebook,python3.10),可调用相关机器学习库
对多次降雨事件归一化后的无量纲 时间-降雨序列曲线如下图所示:
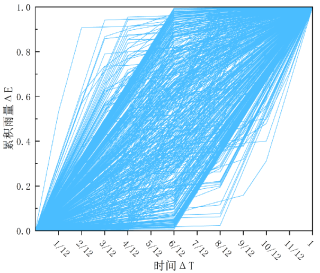
具体分类的原因和目的可参照这篇论文:Stochastic generation of daily rainfall events: A single-site rainfall model
with Copula-based joint simulation of rainfall characteristics and
classification and simulation of rainfall patterns
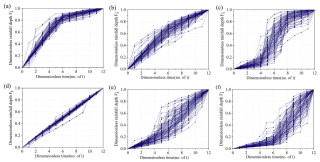
聚类的结果类似下面这样,5-7种
归一化数据可由以下链接下载通过百度网盘分享的文件:归一化结果.xl…
链接:https://pan.baidu.com/s/16T2NZaKBgNbw9W4c7HoAyw
提取码:mu5r








