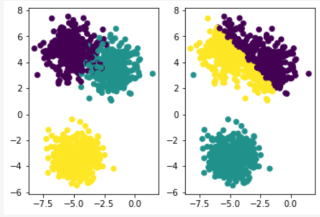
kmeans++聚类聚成这样合理吗
聚类的算法代码如下
class Kmeans:
def __init__(self, k, threshold=1e-5):
self.k = k
self.threshold = threshold
def centroid_init(self,X):
centroids = []
centroids.append(X[np.random.choice(X.shape[0])])
for i in range(self.k-1):
D = []
for x in X:
D.append(np.min([np.linalg.norm(x - c) for c in centroids]))
centroids.append(X[np.argmax(D)])
return np.array(centroids)
def train(self, X):
# 初始化聚类中心
self.centroids = self.centroid_init(X)
y_pred = np.zeros(shape=(X.shape[0],))
while True:
# 涂色
for i, x in enumerate(X):
y_pred[i] = self.predict(x)
# 计算新的聚类中心
new_centroids = self.centroids.copy()
for i in range(self.k):
new_centroids[i] = X[y_pred==i].mean()
# 如果聚类中心位置基本没有变化,那么终止
if np.max(np.abs(new_centroids - self.centroids)) < self.threshold:
break
# 否则更新聚类中心,重复上述步骤
self.centroids = new_centroids
return y_pred
def predict(self, x):
dis = []
# 计算每个样本与中心的距离
for c in self.centroids:
dis.append(np.linalg.norm(x - c))
# 将样本索引添加到距离最小的中心对应的分类中
return np.argmin(dis)
下图左边是原数据分布,右边是上面的算法生成的聚类分布