
训练模型的时候发现训练越长时间,反而效果不好。
训练了8小时的DQN架构的模型比不过4小时的,有哪位资深博主能解释一下吗?

强化学习训练DQN模型

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

2条回答 默认 最新

 关注不知道你这个问题是否已经解决, 如果还没有解决的话:
关注不知道你这个问题是否已经解决, 如果还没有解决的话:- 你看下这篇博客吧, 应该有用👉 :麻雀虽小,五脏俱全,100行代码实现最简单的DQN
- 除此之外, 这篇博客: 从零搭建强化学习DQN框架中的 训练效果展示 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
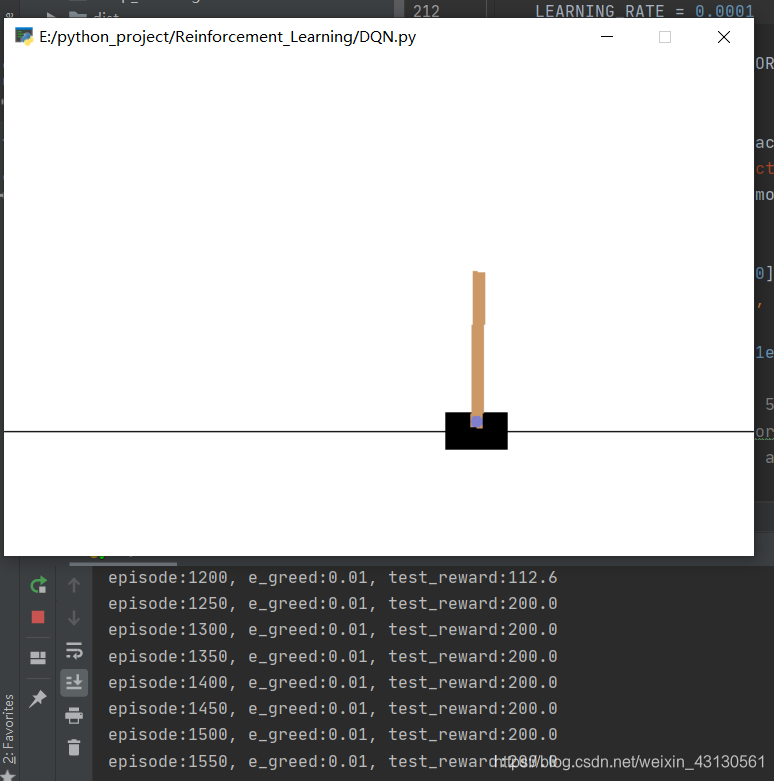
训练一段时间之后,test_reward可以达到200分,此时倒立摆可以稳定地束起来(读者可以自行调节learning_rate,网络模型查看不同效果) - 以下回答来自chatgpt:
问题的现象是训练时间越长,模型的效果反而越差。这可能是由于以下原因导致的:
-
过拟合:训练时间长可能导致模型在训练数据上过度拟合,使得在新的数据上表现差。可以通过增加数据集的多样性,增加正则化惩罚项,或使用早停策略等方式来减少过拟合。
-
学习率设置不合适:学习率过大可能导致模型在训练过程中收敛不稳定,学习率过小可能导致收敛过慢。可以尝试调整学习率的大小,或使用自适应学习率的优化算法,如Adam。
-
DQN架构的不稳定性:DQN算法本身存在训练不稳定的问题,表现为训练开始时,模型的效果会很差,然后逐渐收敛。可以尝试使用经验回放、目标网络等方法来缓解这个问题。
-
模型的超参数选择:模型的超参数选择可能会影响模型的性能,如网络结构、训练参数等。可以尝试调整超参数的选择,比如调整神经网络的层数、神经元个数等。
综上所述,可以尝试以下解决方案来解决该问题:
-
增加训练数据的多样性,如通过引入不同的游戏状态、调整游戏环境等来增加多样性。
-
调整学习率的大小,可以尝试使用自适应学习率的优化算法,如Adam。
-
使用经验回放和目标网络等方法来缓解DQN算法的不稳定性问题。
-
调整模型的超参数选择,可以尝试调整神经网络的层数、神经元个数等。
如果以上方法都不能解决问题,可能需要进一步分析模型训练过程中的其他因素,比如数据预处理、网络结构等,或者考虑尝试其他的强化学习算法。
-
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
- 2023-06-23 15:42《基于强化学习DQN的超级玛丽游戏训练:深入解析与实践》 强化学习(Reinforcement Learning,RL)是人工智能领域的重要分支,它通过与环境的交互,学习如何在特定环境中做出最优决策。深度强化学习(Deep ...
- 2024-02-15 13:23在恶意流量检测的场景下,每个网络数据包可以视为环境的一个状态,智能体(即我们的DQN模型)需要学习如何根据数据包的特征(如源IP、目的IP、端口号、协议类型等)来决定是否将其标记为恶意流量。训练过程中,智能...
- 2025-01-11 21:21deephub的博客 本研究展示了强化学习在游戏人工智能领域的应用潜力。通过具体项目实践,我们期望能够推动该领域的研究发展,并激发更多研究者的兴趣。如需深入了解本项目的技术细节,请参考下方附录和完整的源代码。神经网络架构本...
- 2024-04-23 16:43AGI大模型与大数据研究院的博客 深度强化学习和分布式训练框架是当前人工智能领域的热门研究方向。随着计算资源的增加和算法的发展,我相信它们将在未来解决更多复杂的问题。然而,我们也面临着一些挑战。例如,深度强化学习的稳定性和可解释性,...
- 2026-03-08 20:01内容概要:本文围绕基于深度强化学习DQN构建充电汽车能量模型的研究展开,提出了一种利用深度Q网络(DQN)优化电动汽车充电行为与能量管理的解决方案。研究通过构建合理的马尔可夫决策过程(MDP)框架,将充电功率、...
- 2024-10-15 18:56强化学习是一类通过与环境互动来学习最优策略的方法,在人工智能领域应用广泛。...随着深度学习和强化学习研究的进一步深入,DQN及其衍生算法将会在更多实际问题中得到应用,推动人工智能技术的发展。
- 2023-07-28 15:34这个代理使用DQN算法来学习最优的决策策略。 2.代理的目标是找到所有可能状态的最佳最终状态的组合,而不是传统方法中找到特定状态的最佳动作。 3.通过使用深度神经网络来逼近Q函数,代理可以处理大型状态空间的问题...
- 2025-08-12 20:02在使用PyTorch构建DQN模型时,首先需要了解强化学习中的基本概念,如智能体(Agent)、环境(Environment)、状态(State)、动作(Action)和奖励(Reward)。智能体通过与环境交互来学习如何根据当前状态选择最优...
- 2025-08-13 01:45在开发基于深度强化学习DQN的FlappyBird游戏人工智能过程中,研究人员首先需要构建一个环境模型,即FlappyBird游戏环境,其中包括小鸟的动态模型、管道的生成逻辑、碰撞检测等。接着,需要设计DQN网络结构,包括状态...
- 2025-04-09 22:59贝塔西塔的博客 Double DQN 是 DQN 的重要改进,通过解耦...尽管存在局限性,但其简洁高效的实现使其成为深度强化学习中的基础组件,常与其他技术(如 Prioritized Replay、Dueling DQN)结合,形成更强大的算法(如 Rainbow DQN)。
- 2022-12-30 15:48在人工智能领域,强化学习作为一种重要的学习方式,近年来受到了广泛的关注。尤其是Deep Q-Network(DQN)算法的提出,为解决复杂的决策问题提供了新的思路。本文将围绕"走迷宫"这一实际应用场景,深入解析DQN算法的...
- 2025-04-06 09:15贝塔西塔的博客 Hierarchical DQN通过层次化分解任务,结合时间与目标抽象,显著提升了复杂任务中的学习效率。通过高层与底层的协同,将稀疏奖励问题转化为密集的子目标追踪,是解决长期依赖与高维决策问题的有效范式。本文详细解释...
- 2024-04-12 09:14基于强化学习DQN算法+训练AI模型来玩合成大西瓜游戏python源码+项目说明(提供Keras版本和PARL(paddle)版本).zip基于强化学习DQN算法+训练AI模型来玩合成大西瓜游戏python源码+项目说明(提供Keras版本和PARL...
- 没有解决我的问题, 去提问


问题事件
 系统已结题
8月2日
系统已结题
8月2日 已采纳回答
7月25日
已采纳回答
7月25日-
创建了问题
7月20日