 变成乱码了。
变成乱码了。
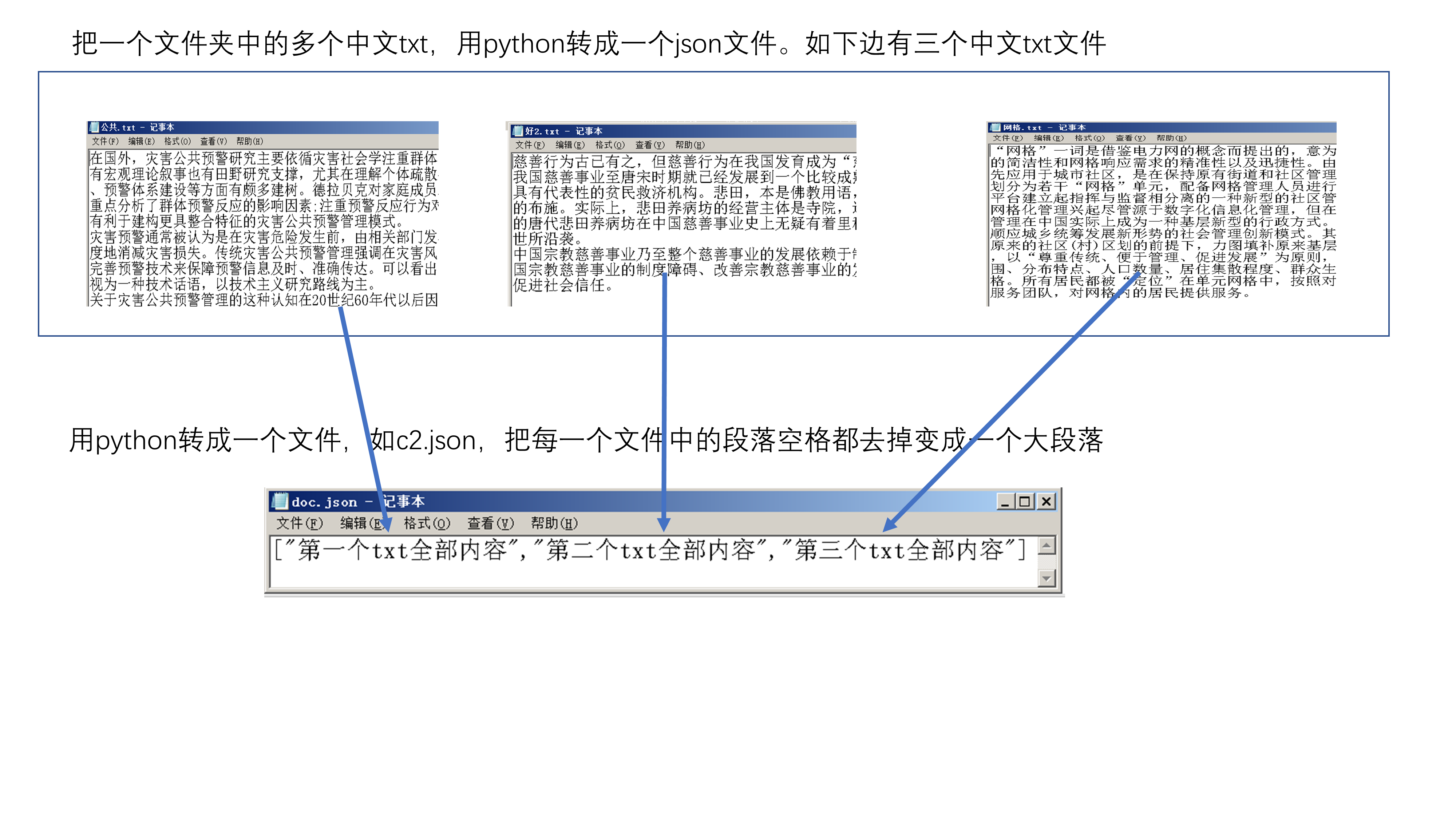
节选了文件夹中的几个中文文本文档,如同上面的形式,怎么能处理成一个json文件呢?看到网上说为了不报错,得转成utf-8格式,/r/n 替换成/n而且得加上 ensure__ascii=False,但是我不知道怎么加,谢谢各位前辈了!

变成乱码了。
节选了文件夹中的几个中文文本文档,如同上面的形式,怎么能处理成一个json文件呢?看到网上说为了不报错,得转成utf-8格式,/r/n 替换成/n而且得加上 ensure__ascii=False,但是我不知道怎么加,谢谢各位前辈了!
 分享
分享
文本内容:
安徽
江苏
浙江
with open("F:/test/test.txt","rb") as f:
print(f.read())
输出:
b'\xe5\xae\x89\xe5\xbe\xbd\n\xe6\xb1\x9f\xe8\x8b\x8f\n\xe6\xb5\x99\xe6\xb1\x9f\n\n\xe4\xb8\x8a\xe6\xb5\xb7'
with open("F:/ftp/downloads/downloadfile/test.txt","rb") as f:
print(f.read().decode('utf-8'))
输出:
安徽
江苏
浙江
上海
with open("F:/ftp/downloads/downloadfile/test.txt","rb") as f:
lines=f.readlines()
a=[]
for line in lines:
line=line.strip()
a.append(line.decode('utf-8'))
print(''.join(a))
输出:
安徽江苏浙江上海
够清楚了吧?
写个循环把所有txt读一遍,存成字典就可以了。
import os
import json
filelist=os.listdir('F:/test1') ##获取txt所在文件夹的所有文件,我放了三个txt,格式跟上面差不多
txts=[]
##循环追加到list中
for i in filelist:
with open("F:/test1/"+i,"rb") as f:
lines=f.readlines()
a=[]
for line in lines:
line=line.strip()
a.append(line.decode('utf-8'))
txt=''.join(a)
txts.append(txt)
f.close()
##输出:['安徽江苏浙江上海', '南京无锡苏州南通', '杭州宁波温州']
#存入json文件
with open('txts.json', 'w') as f:
json.dump(txts, f)

