任务是拟合二输入线性函数y=x1+2*x2,先用TensorFlow读取csv文件,然后训练神经网络,代码如下:
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
import functools
train_file_path = "./datas/二输入数据表.csv"
test_file_path = "./datas/二输入测试数据表.csv"
LABEL_COLUMN = 'y'
import tensorflow as tf
OUTPUT = 'y'
def get_dataset(file_path):
dataset = tf.data.experimental.make_csv_dataset(
file_path,
batch_size=4,
label_name=OUTPUT,
num_epochs=1,
ignore_errors=True)
return dataset
raw_train_data = get_dataset(train_file_path)
raw_test_data = get_dataset(test_file_path)
examples,labels = next(iter(raw_train_data))
print("EXAMPLES: \n",examples,"\n")
print("LABELS: \n",labels)
def process_continuous_data(mean,data):
data = tf.cast(data,tf.float32) * 1/(2*mean)
return tf.reshape(data,[-1,1])
MEANS = {
'x1' : 7.149044577,
'x2' : 13.07613598,
'y' : 33.30131655
}
numerical_columns = []
for feature in MEANS.keys():
num_col = tf.feature_column.numeric_column(
feature,normalizer_fn=functools.partial(process_continuous_data,MEANS[feature]))
numerical_columns.append(num_col)
numerical_columns
preprocessing_layer = tf.keras.layers.DenseFeatures(numerical_columns)
model = Sequential([
preprocessing_layer,
tf.keras.layers.Dense(4,activation='relu'),
tf.keras.layers.Dense(1)
]
)
model.compile(optimizer = 'rmsprop',loss="mse",metrics=['mae'])
model.fit(raw_train_data,epochs=20)
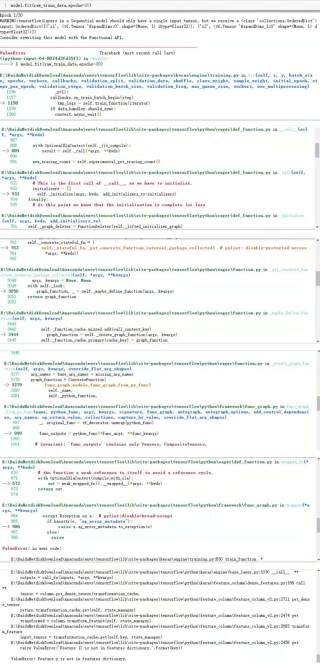
报错情况: