

从b站一个up主那里copy的说是pytorch官网的FCN模型想要学习,但是有一些问题需要请教各位资深专家。
一丶整个项目要求是numpy==1.21.3 torch==1.10.0 torchvision==0.11.1,但是目前我已经下载不到低版本的torch模块了,所以请问高版本的兼容低版本的项目么?
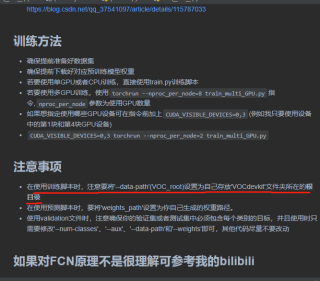
二丶这个项目推荐使用官方的数据集“VOCtrainval_11-May-2012”,我将代码原封不动运行后出现了“AssertionError: path '/data/VOCdevkit\VOC2012' does not exist.”的错误,项目readme中也明确说明要更改根目录,但是我不知道怎么改,在代码中也没有找到所谓的“'--data-path'(VOC_root)”。
b站博主的视频说要在train.py靠后部分和my_dataset.py靠前部分中改东西,代码已经放在下面具体位置我已经用注释的方式标注,但是我不会改。
#train.py 训练模块
import os
import time
import datetime
import torch
from src import fcn_resnet50
from train_utils import train_one_epoch, evaluate, create_lr_scheduler
from my_dataset import VOCSegmentation
import transforms as T
class SegmentationPresetTrain:
def __init__(self, base_size, crop_size, hflip_prob=0.5, mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)):
min_size = int(0.5 * base_size)
max_size = int(2.0 * base_size)
trans = [T.RandomResize(min_size, max_size)]
if hflip_prob > 0:
trans.append(T.RandomHorizontalFlip(hflip_prob))
trans.extend([
T.RandomCrop(crop_size),
T.ToTensor(),
T.Normalize(mean=mean, std=std),
])
self.transforms = T.Compose(trans)
def __call__(self, img, target):
return self.transforms(img, target)
class SegmentationPresetEval:
def __init__(self, base_size, mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)):
self.transforms = T.Compose([
T.RandomResize(base_size, base_size),
T.ToTensor(),
T.Normalize(mean=mean, std=std),
])
def __call__(self, img, target):
return self.transforms(img, target)
def get_transform(train):
base_size = 520
crop_size = 480
return SegmentationPresetTrain(base_size, crop_size) if train else SegmentationPresetEval(base_size)
def create_model(aux, num_classes, pretrain=True):
model = fcn_resnet50(aux=aux, num_classes=num_classes)
if pretrain:
weights_dict = torch.load("./fcn_resnet50_coco.pth", map_location='cpu')
if num_classes != 21:
# 官方提供的预训练权重是21类(包括背景)
# 如果训练自己的数据集,将和类别相关的权重删除,防止权重shape不一致报错
for k in list(weights_dict.keys()):
if "classifier.4" in k:
del weights_dict[k]
missing_keys, unexpected_keys = model.load_state_dict(weights_dict, strict=False)
if len(missing_keys) != 0 or len(unexpected_keys) != 0:
print("missing_keys: ", missing_keys)
print("unexpected_keys: ", unexpected_keys)
return model
def main(args):
device = torch.device(args.device if torch.cuda.is_available() else "cpu")
batch_size = args.batch_size
# segmentation nun_classes + background
num_classes = args.num_classes + 1
# 用来保存训练以及验证过程中信息
results_file = "results{}.txt".format(datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
# VOCdevkit -> VOC2012 -> ImageSets -> Segmentation -> train.txt
train_dataset = VOCSegmentation(args.data_path,
year="2012",
transforms=get_transform(train=True),
txt_name="train.txt")
# VOCdevkit -> VOC2012 -> ImageSets -> Segmentation -> val.txt
val_dataset = VOCSegmentation(args.data_path,
year="2012",
transforms=get_transform(train=False),
txt_name="val.txt")
num_workers = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8])
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
num_workers=num_workers,
shuffle=True,
pin_memory=True,
collate_fn=train_dataset.collate_fn)
val_loader = torch.utils.data.DataLoader(val_dataset,
batch_size=1,
num_workers=num_workers,
pin_memory=True,
collate_fn=val_dataset.collate_fn)
model = create_model(aux=args.aux, num_classes=num_classes)
model.to(device)
params_to_optimize = [
{"params": [p for p in model.backbone.parameters() if p.requires_grad]},
{"params": [p for p in model.classifier.parameters() if p.requires_grad]}
]
if args.aux:
params = [p for p in model.aux_classifier.parameters() if p.requires_grad]
params_to_optimize.append({"params": params, "lr": args.lr * 10})
optimizer = torch.optim.SGD(
params_to_optimize,
lr=args.lr, momentum=args.momentum, weight_decay=args.weight_decay
)
scaler = torch.cuda.amp.GradScaler() if args.amp else None
# 创建学习率更新策略,这里是每个step更新一次(不是每个epoch)
lr_scheduler = create_lr_scheduler(optimizer, len(train_loader), args.epochs, warmup=True)
if args.resume:
checkpoint = torch.load(args.resume, map_location='cpu')
model.load_state_dict(checkpoint['model'])
optimizer.load_state_dict(checkpoint['optimizer'])
lr_scheduler.load_state_dict(checkpoint['lr_scheduler'])
args.start_epoch = checkpoint['epoch'] + 1
if args.amp:
scaler.load_state_dict(checkpoint["scaler"])
start_time = time.time()
for epoch in range(args.start_epoch, args.epochs):
mean_loss, lr = train_one_epoch(model, optimizer, train_loader, device, epoch,
lr_scheduler=lr_scheduler, print_freq=args.print_freq, scaler=scaler)
confmat = evaluate(model, val_loader, device=device, num_classes=num_classes)
val_info = str(confmat)
print(val_info)
# write into txt
with open(results_file, "a") as f:
# 记录每个epoch对应的train_loss、lr以及验证集各指标
train_info = f"[epoch: {epoch}]\n" \
f"train_loss: {mean_loss:.4f}\n" \
f"lr: {lr:.6f}\n"
f.write(train_info + val_info + "\n\n")
save_file = {"model": model.state_dict(),
"optimizer": optimizer.state_dict(),
"lr_scheduler": lr_scheduler.state_dict(),
"epoch": epoch,
"args": args}
if args.amp:
save_file["scaler"] = scaler.state_dict()
torch.save(save_file, "save_weights/model_{}.pth".format(epoch))
total_time = time.time() - start_time
total_time_str = str(datetime.timedelta(seconds=int(total_time)))
print("training time {}".format(total_time_str))
def parse_args():
import argparse
parser = argparse.ArgumentParser(description="pytorch fcn training")
parser.add_argument("--data-path", default="/data/", help="VOCdevkit root") #b站博主视频说是在这改但是我不知道怎么改。。。
parser.add_argument("--num-classes", default=20, type=int)
parser.add_argument("--aux", default=True, type=bool, help="auxilier loss")
parser.add_argument("--device", default="cuda", help="training device")
parser.add_argument("-b", "--batch-size", default=4, type=int)
parser.add_argument("--epochs", default=30, type=int, metavar="N",
help="number of total epochs to train")
parser.add_argument('--lr', default=0.0001, type=float, help='initial learning rate')
parser.add_argument('--momentum', default=0.9, type=float, metavar='M',
help='momentum')
parser.add_argument('--wd', '--weight-decay', default=1e-4, type=float,
metavar='W', help='weight decay (default: 1e-4)',
dest='weight_decay')
parser.add_argument('--print-freq', default=10, type=int, help='print frequency')
parser.add_argument('--resume', default='', help='resume from checkpoint')
parser.add_argument('--start-epoch', default=0, type=int, metavar='N',
help='start epoch')
# Mixed precision training parameters
parser.add_argument("--amp", default=False, type=bool,
help="Use torch.cuda.amp for mixed precision training")
args = parser.parse_args()
return args
if __name__ == '__main__':
args = parse_args()
if not os.path.exists("./save_weights"):
os.mkdir("./save_weights")
main(args)
```__
```python
#my_dataset.py模块
import os
import torch.utils.data as data
from PIL import Image
class VOCSegmentation(data.Dataset):
def __init__(self, voc_root, year="2012", transforms=None, txt_name: str = "train.txt"): #博主说是在这也要改“voc_root"的参数我也不会改。。。
super(VOCSegmentation, self).__init__()
assert year in ["2007", "2012"], "year must be in ['2007', '2012']"
root = os.path.join(voc_root, "VOCdevkit", f"VOC{year}")
assert os.path.exists(root), "path '{}' does not exist.".format(root)
image_dir = os.path.join(root, 'JPEGImages')
mask_dir = os.path.join(root, 'SegmentationClass')
txt_path = os.path.join(root, "ImageSets", "Segmentation", txt_name)
assert os.path.exists(txt_path), "file '{}' does not exist.".format(txt_path)
with open(os.path.join(txt_path), "r") as f:
file_names = [x.strip() for x in f.readlines() if len(x.strip()) > 0]
self.images = [os.path.join(image_dir, x + ".jpg") for x in file_names]
self.masks = [os.path.join(mask_dir, x + ".png") for x in file_names]
assert (len(self.images) == len(self.masks))
self.transforms = transforms
def __getitem__(self, index):
"""
Args:
index (int): Index
Returns:
tuple: (image, target) where target is the image segmentation.
"""
img = Image.open(self.images[index]).convert('RGB')
target = Image.open(self.masks[index])
if self.transforms is not None:
img, target = self.transforms(img, target)
return img, target
def __len__(self):
return len(self.images)
@staticmethod
def collate_fn(batch):
images, targets = list(zip(*batch))
batched_imgs = cat_list(images, fill_value=0)
batched_targets = cat_list(targets, fill_value=255)
return batched_imgs, batched_targets
def cat_list(images, fill_value=0):
# 计算该batch数据中,channel, h, w的最大值
max_size = tuple(max(s) for s in zip(*[img.shape for img in images]))
batch_shape = (len(images),) + max_size
batched_imgs = images[0].new(*batch_shape).fill_(fill_value)
for img, pad_img in zip(images, batched_imgs):
pad_img[..., :img.shape[-2], :img.shape[-1]].copy_(img)
return batched_imgs
# dataset = VOCSegmentation(voc_root="/data/", transforms=get_transform(train=True))
# d1 = dataset[0]
# print(d1)







