




输出词向量词汇中总是夹杂着编码
问题相关代码,请勿粘贴截图
from re import A
import warnings
import gensim
from matplotlib.pyplot import get
if name == 'main':
warnings.filterwarnings(action='ignore', category=UserWarning,module='gensim')
model = gensim.models.Word2Vec.load("douluo.model")
word = 'ᠤᠳᠠᠲᠠᠯ\u180eᠠ'
result = model.wv.similar_by_word(word)
print('输入词为: '+word)
if word in model.wv.key_to_index != True:
print('输入的词: ( '+word+' ) 可以在词表中找到')
else:
print('这个词在词嵌入表中无法找到')
print("跟 "+word+" 最相近的词:")
print(type(result))
for i in result:
print(i)
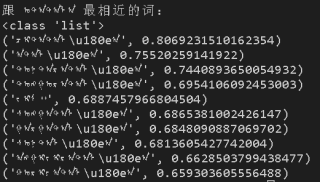
运行结果及报错内容
跟 ᠤᠳᠠᠲᠠᠯᠠ 最相近的词:
<class 'list'>
('ᠴᠢᠳᠠᠲᠠᠯ\u180eᠠ', 0.8069231510162354)
('ᠠᠲᠠᠯ\u180eᠠ', 0.75520259141922)
('ᠳᠤᠨᠳᠠᠷᠠᠲᠠᠯ\u180eᠠ', 0.7440893650054932)
('ᠲᠣᠩᠭᠣᠷᠠᠲᠠᠯ\u180eᠠ', 0.6954106092453003)
('ᠵᠢᠮ᠃', 0.6887457966804504)
('ᠰᠤᠩᠭᠠᠲᠠᠯ\u180eᠠ', 0.6865381002426147)
('ᠭᠠᠷᠭᠠᠲᠠᠯ\u180eᠠ', 0.6848090887069702)
('ᠰᠤᠨᠲᠠᠯ\u180eᠠ', 0.6813605427742004)
('ᠠᠩᠭᠢᠵᠢᠷᠠᠲᠠᠯ\u180eᠠ', 0.6628503799438477)
('ᠬᠤᠷᠢᠶᠠᠲᠠᠯ\u180eᠠ', 0.659303605556488)
我的解答思路和尝试过的方法
我发现
word = 'ᠤᠳᠠᠲᠠᠯ\u180eᠠ'
print('输入词为: '+word)
得到输出是:
输入词为: ᠤᠳᠠᠲᠠᠯᠠ
把带有编码的词输入再输出一下就可以得到没有编码的词,我写到文件夹再读进来发现依旧是带编码的
我想要达到的结果
怎么可以直接输出不带编码的






























