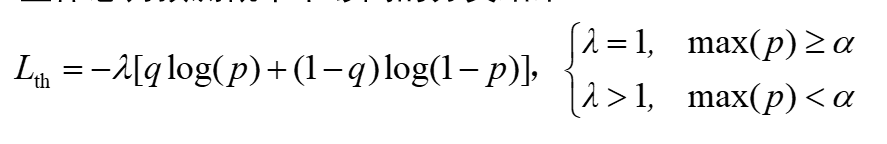

keras阈值损失函数(Threshold loss function)怎么写呢?

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

1条回答 默认 最新

- 2018-11-19 15:53小北小白的博客 参考:... 个人觉得,整个检测最重要的就是darknet网络与损失函数的设计。 def yolo_loss(args, anchors, num_classes, ignore_thresh=.5, print_loss=False):...
- 2023-10-10 10:57无水先生的博客 TensorFlow 2发布已经接近5年时间,不仅继承了Keras快速上手和易于使用的特性,同时还扩展了原有Keras所不支持的分布式训练的特性。3大设计原则:简化概念,海纳百川,构建生态.这是本系列的第三部分,我们将创建...
- 2025-02-11 16:22蟹黄味蚕豆的博客 在深度学习中,损失函数(也称为成本函数或目标函数)是一个关键组件,用于量化神经网络生成的预测输出与给定数据集中的实际目标值之间的差异。根据问题的性质,会使用不同类型的损失函数,例如回归问题使用均方误差...
- 2021-05-20 00:06数据派THU的博客 作者:Arjun Sarkar翻译:陈之炎校对:欧阳锦本文约1900字,建议阅读8分钟本文带你学习使用Python中的wrapper函数和OOP来编写自定义损失函数。 标签:...
- 2020-09-15 01:25Big黄勇的博客 损失函数变大George Orwell’s novella Animal Farm includes the memorable line… 乔治·奥威尔(George Orwell)的中篇小说《动物农场》(Animal Farm)包括令人难忘的系列…… all animals are equal, but some ...
- 2021-06-16 13:16张博208的博客 代价敏感损失函数的函数特性分析 0x1:原始无偏损失函数函数性质 0x2:分类代价在损失函数外(Classification cost outside of loss function) 0x3:分类代价在损失函数内(Classification cost inside of loss ...
- 2025-03-27 10:09空云风语的博客 Keras 3 :AI 使用图神经网络和 LSTM 进行交通流量预测
- 2020-09-17 18:11weixin_26716857的博客 蒙受损失 (Coming to terms with loss) Photo by Tom Pumford on Unsplash Tom Pumford在Unsplash上拍摄的照片 When it comes to deep learning, the loss function determines what the algorithm is trying to ...
- 2025-06-06 13:39AI原生应用开发的博客 异常检测就是AI界的“侦探”,专门从数据里揪出这些“不按套路出牌”的异常点。本文将覆盖异常检测的核心概念、主流算法、实战应用,帮您从“听说过”到“会用它”。本文将按照“概念→原理→实战→应用”的逻辑展开...
- 2020-12-21 11:45weixin_39623355的博客 本文主要介绍如何在Python中使用TensorFlow和Keras构建卷积神经网络。卷积神经网络是过去十年中深度学习成为一大热点的部分原因。今天将使用TensorFlow的eager API来训练图像分类器,以辨别图像内容是狗还是猫。人工...
- 没有解决我的问题, 去提问
