
在配置“kmeans对自己的图像数据集聚类(及肘部法求最佳K值)”代码时(详细代码可见https://blog.csdn.net/hnu_zzt/article/details/84788131)
import torch
from torch.utils import data
from PIL import Image
import numpy as np
from torchvision import transforms
from numpy import *
transform = transforms.Compose([
transforms.ToTensor(), # 将图片转换为Tensor,归一化至[0,1]
# transforms.Normalize(mean=[.5, .5, .5], std=[.5, .5, .5]) # 标准化至[-1,1]
])
# 定义自己的数据集合
class FlameSet(data.Dataset):
def __init__(self, root):
# 所有图片的绝对路径
imgs = os.listdir(root)
self.imgs = [os.path.join(root, k) for k in imgs]
self.transforms = transform
def __getitem__(self, index):
img_path = self.imgs[index]
pil_img = Image.open(img_path)
if self.transforms:
data = self.transforms(pil_img)
else:
pil_img = np.asarray(pil_img)
data = torch.from_numpy(pil_img)
return data
def __len__(self):
return len(self.imgs)
# 计算两个矩阵的距离
def euclDistance(vector1, vector2):
return sqrt(sum(power(vector2 - vector1, 2)))
# 在样本集中随机选取k个样本点作为初始质心
def initCentroids(dataSet, k):
numSamples, dim = dataSet.shape # 矩阵的行数、列数
centroids = zeros((k, dim)) # 感觉要不要你都可以
for i in range(k):
index = int(random.uniform(0, numSamples)) # 随机产生一个浮点数,然后将其转化为int型
centroids[i, :] = dataSet[index, :]
return centroids
# k-means cluster
# dataSet为一个矩阵
# k为将dataSet矩阵中的样本分成k个类
def kmeans(dataSet, k):
numSamples = dataSet.shape[0] # 读取矩阵dataSet的第一维度的长度,即获得有多少个样本数据
# first column stores which cluster this sample belongs to,
# second column stores the error between this sample and its centroid
clusterAssment = mat(zeros((numSamples, 2))) # 得到一个N*2的零矩阵
clusterChanged = True
上述代码均未见报错
## step 1: init centroids
centroids = initCentroids(dataSet, k) # 在样本集中随机选取k个样本点作为初始质心
此行代码报错,内容如下

while clusterChanged:
clusterChanged = False
## for each sample
for i in range(numSamples): # range
minDist = 100000.0
minIndex = 0
## for each centroid
## step 2: find the centroid who is closest
# 计算每个样本点与质点之间的距离,将其归内到距离最小的那一簇
for j in range(k):
distance = euclDistance(centroids[j, :], dataSet[i, :])
if distance < minDist:
minDist = distance
minIndex = j
此行代码报错,内容如下
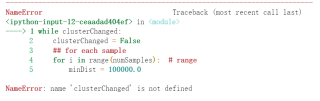
求解决方法~







