
在yolov3下训练自己的数据集卡住
我在进行voc数据集的训练,使用yolov3
并根据这个流程
https://blog.csdn.net/weixin_43818251/article/details/89548583
darknet训练卡住
我使用命令
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74 >> /home/heying/darknet/scripts/VOCdevkit/VOC2020/traffic_light.log
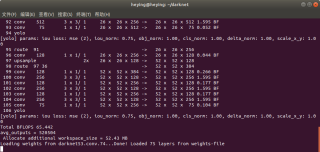
就是这个终端一直是这样的,这正常吗
问题相关代码
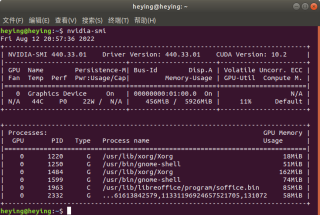
显卡
使用的cfg/voc.data文件
classes= 3
train = /home/heying/darknet/scripts/2020_train.txt
valid = /home/heying/darknet/scripts/2020_test.txt
names = data/voc2020.names
backup = /home/pjreddie/backup/
使用的cfg/yolov3-voc.cfg文件
[net]
# Testing
batch=1
subdivisions=1
# Training #训练模式 每次前向图片的数目=batch/subdivisions
#关于batch与subdivision:在训练输出中,训练迭代包括8组,
#这些batch样本又被平均分成subdivision=8次送入网络参与训练,
#以减轻内存占用的压力;batch越大,训练效果越好,subdivision越大,占用内存压力越小
# batch=64
# subdivisions=16
#网络输入的宽、高、通道数这三个参数中,要求width==height, 并且为32的倍数
#大分辨率可以检测到更加细小的物体,从而影响precision
width=416 #只能是32的倍数
height=416
channels=3
momentum=0.9 #动量,影响梯度下降到最优的速度,一般默认0.9
decay=0.0005 #权重衰减正则系数,防止过拟合
angle=0 #旋转角度,从而生成更多训练样本
saturation = 1.5 #调整饱和度,从而生成更多训练样本
exposure = 1.5 #调整曝光度,从而生成更多训练样本
hue=.1 #调整色调,从而生成更多训练样本
#学习率决定了权值更新的速度,学习率大,更新的就快,但太快容易越过最优值,
#而学习率太小又更新的慢,效率低,一般学习率随着训练的进行不断更改,
#先高一点,然后慢慢降低,一般在0.01--0.001
learning_rate=0.001
#学习率控制的参数,在迭代次数小于burn_in时,其学习率的更新有一种方式,大于burn_in时,才采用policy的更新方式
burn_in=1000
#迭代次数,1000次以内,每训练100次保存一次权重,1000次以上,每训练10000次保存一次权重
max_batches = 50200
policy=steps # 学习率策略,学习率下降的方式
steps=40000,45000 #学习率变动步长
#学习率变动因子:如迭代到40000次时,学习率衰减十倍,45000次迭代时,学习率又会在前一个学习率的基础上衰减十倍
scales=.1,.1
[convolutional]
batch_normalize=1 #BN
filters=32 #卷积核数目
size=3 #卷积核尺寸
stride=1 #做卷积运算的步长
#如果pad为0,padding由 padding参数指定;
#如果pad为1,padding大小为size/2,
#padding应该是对输入图像左边缘拓展的像素数量
pad=1
activation=leaky #激活函数类型
# Downsample
【后面的没有修改】
在卡住的过程中的log文件
CUDNN_HALF=1
0,1
yolov3-voc
net.optimized_memory = 0
mini_batch = 1, batch = 1, time_steps = 1, train = 1
Create CUDA-stream - 0
Create cudnn-handle 0
CUDNN_HALF=1
0,1
yolov3-voc
net.optimized_memory = 0
mini_batch = 1, batch = 1, time_steps = 1, train = 1
Create CUDA-stream - 0
Create cudnn-handle 0
seen 64, trained: 0 K-images (0 Kilo-batches_64)
CUDA status Error: file: ./src/dark_cuda.c : () : line: 38 : build time: Mar 7 2022 - 16:11:01
CUDA Error: invalid device ordinal
CUDNN_HALF=1
0
yolov3-voc
net.optimized_memory = 0
mini_batch = 1, batch = 1, time_steps = 1, train = 1
Create CUDA-stream - 0
Create cudnn-handle 0
CUDNN_HALF=1
0
yolov3-voc
net.optimized_memory = 0
mini_batch = 1, batch = 1, time_steps = 1, train = 1
Create CUDA-stream - 0
Create cudnn-handle 0
CUDNN_HALF=1
yolov3-voc
net.optimized_memory = 0
mini_batch = 1, batch = 1, time_steps = 1, train = 1
Create CUDA-stream - 0
Create cudnn-handle 0
CUDNN_HALF=1
yolov3-voc
net.optimized_memory = 0
mini_batch = 1, batch = 1, time_steps = 1, train = 1
Create CUDA-stream - 0
Create cudnn-handle 0
CUDNN_HALF=1
yolov3-voc
net.optimized_memory = 0
mini_batch = 1, batch = 1, time_steps = 1, train = 1
Create CUDA-stream - 0
Create cudnn-handle 0
我的解答思路和尝试过的方法
权重文件换成了yolov3.weights也还是卡住
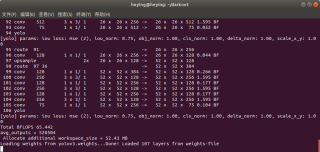
说明
使用的voc数据集在我的另一台nvidia AGX 中jetson-inference里训练是正常的,出来的模型识别效果良好
使用的主机是英特尔(Intel)NUC11PHKi7CAA幻影峡谷11代酷睿i7RTX2060独显迷你电脑主机
https://item.jd.com/10028216825202.html
现在临时想到能够提供的暂时这些,如有解决方案我将不胜感激






