
yolov7的train.py测试完成后,生成的函数图如下,他们是不是不太正确,我也搜不到关于yolov7函数图的介绍。训练自己的图片时,检测的类名几乎全错
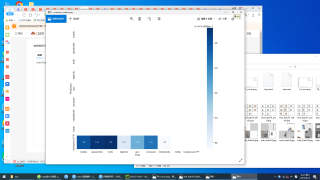
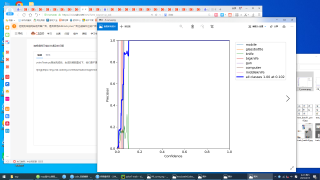
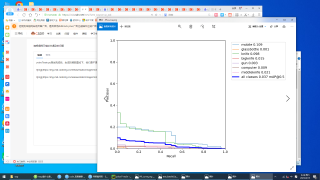
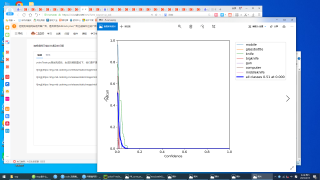
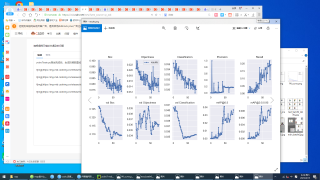

yolov7的train.py测试完成后,生成的函数图如下,他们是不是不太正确,我也搜不到关于yolov7函数图的介绍。训练自己的图片时,检测的类名几乎全错
 分享
分享
 关注
关注
def main(opt, callbacks=Callbacks()):
# Checks
set_logging(RANK)
if RANK in [-1, 0]:
# 输出所有训练opt参数
print_args(FILE.stem, opt)
# 检查代码版本是否是最新的
check_git_status()
# 检查requirements.txt所需包是否都满足
check_requirements(exclude=['thop'])
logging和wandb初始化
# Resume
if opt.resume and not check_wandb_resume(opt) and not opt.evolve: # resume an interrupted run
# 使用断点续训 就从last.pt中读取相关参数
# 如果resume是str,则表示传入的是模型的路径地址
# 如果resume是True,则通过get_lastest_run()函数找到runs为文件夹中最近的权重文件last.pt
ckpt = opt.resume if isinstance(opt.resume, str) else get_latest_run() # specified or most recent path
assert os.path.isfile(ckpt), 'ERROR: --resume checkpoint does not exist'
# 相关的opt参数也要替换成last.pt中的opt参数
with open(Path(ckpt).parent.parent / 'opt.yaml') as f:
opt = argparse.Namespace(**yaml.safe_load(f)) # replace
opt.cfg, opt.weights, opt.resume = '', ckpt, True # reinstate
LOGGER.info(f'Resuming training from {ckpt}')
else:
# 不使用断点续训 就从文件中读取相关参数
opt.data, opt.cfg, opt.hyp = check_file(opt.data), check_yaml(opt.cfg), check_yaml(opt.hyp) # check YAMLs
assert len(opt.cfg) or len(opt.weights), 'either --cfg or --weights must be specified'
if opt.evolve:
opt.project = 'runs/evolve'
opt.exist_ok, opt.resume = opt.resume, False # pass resume to exist_ok and disable resume
# 根据opt.project生成目录
opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok))
判断是否使用断点续训resume, 读取参数
使用断点续训 就从last.pt中读取相关参数;不使用断点续训 就从文件中读取相关参数
# DDP mode
# 选择设备 cpu/cuda:0
device = select_device(opt.device, batch_size=opt.batch_size)
if LOCAL_RANK != -1:
# LOCAL_RANK != -1 进行多GPU训练
from datetime import timedelta
assert torch.cuda.device_count() > LOCAL_RANK, 'insufficient CUDA devices for DDP command'
assert opt.batch_size % WORLD_SIZE == 0, '--batch-size must be multiple of CUDA device count'
assert not opt.image_weights, '--image-weights argument is not compatible with DDP training'
assert not opt.evolve, '--evolve argument is not compatible with DDP training'
torch.cuda.set_device(LOCAL_RANK)
# 根据GPU编号选择设备
device = torch.device('cuda', LOCAL_RANK)
# 初始化进程组 distributed backend
dist.init_process_group(backend="nccl" if dist.is_nccl_available() else "gloo")
DDP mode设置
# Train
# 不使用进化算法 正常Train
if not opt.evolve:
# 如果不进行超参进化 那么就直接调用train()函数,开始训练
train(opt.hyp, opt, device, callbacks)
# 如果是使用多卡训练, 那么销毁进程组
if WORLD_SIZE > 1 and RANK == 0:
LOGGER.info('Destroying process group... ')
dist.destroy_process_group()
不进行算法,正常训练
else:
# Hyperparameter evolution metadata (mutation scale 0-1, lower_limit, upper_limit)
meta = {'lr0': (1, 1e-5, 1e-1), # initial learning rate (SGD=1E-2, Adam=1E-3)
'lrf': (1, 0.01, 1.0), # final OneCycleLR learning rate (lr0 * lrf)
'momentum': (0.3, 0.6, 0.98), # SGD momentum/Adam beta1
'weight_decay': (1, 0.0, 0.001), # optimizer weight decay
'warmup_epochs': (1, 0.0, 5.0), # warmup epochs (fractions ok)
'warmup_momentum': (1, 0.0, 0.95), # warmup initial momentum
'warmup_bias_lr': (1, 0.0, 0.2), # warmup initial bias lr
'box': (1, 0.02, 0.2), # box loss gain
'cls': (1, 0.2, 4.0), # cls loss gain
'cls_pw': (1, 0.5, 2.0), # cls BCELoss positive_weight
'obj': (1, 0.2, 4.0), # obj loss gain (scale with pixels)
'obj_pw': (1, 0.5, 2.0), # obj BCELoss positive_weight
'iou_t': (0, 0.1, 0.7), # IoU training threshold
'anchor_t': (1, 2.0, 8.0), # anchor-multiple threshold
'anchors': (2, 2.0, 10.0), # anchors per output grid (0 to ignore)
'fl_gamma': (0, 0.0, 2.0), # focal loss gamma (efficientDet default gamma=1.5)
'hsv_h': (1, 0.0, 0.1), # image HSV-Hue augmentation (fraction)
'hsv_s': (1, 0.0, 0.9), # image HSV-Saturation augmentation (fraction)
'hsv_v': (1, 0.0, 0.9), # image HSV-Value augmentation (fraction)
'degrees': (1, 0.0, 45.0), # image rotation (+/- deg)
'translate': (1, 0.0, 0.9), # image translation (+/- fraction)
'scale': (1, 0.0, 0.9), # image scale (+/- gain)
'shear': (1, 0.0, 10.0), # image shear (+/- deg)
'perspective': (0, 0.0, 0.001), # image perspective (+/- fraction), range 0-0.001
'flipud': (1, 0.0, 1.0), # image flip up-down (probability)
'fliplr': (0, 0.0, 1.0), # image flip left-right (probability)
'mosaic': (1, 0.0, 1.0), # image mixup (probability)
'mixup': (1, 0.0, 1.0), # image mixup (probability)
'copy_paste': (1, 0.0, 1.0)} # segment copy-paste (probability)
with open(opt.hyp) as f:
hyp = yaml.safe_load(f) # load hyps dict
if 'anchors' not in hyp: # anchors commented in hyp.yaml
hyp['anchors'] = 3
opt.noval, opt.nosave, save_dir = True, True, Path(opt.save_dir) # only val/save final epoch
# ei = [isinstance(x, (int, float)) for x in hyp.values()] # evolvable indices
evolve_yaml, evolve_csv = save_dir / 'hyp_evolve.yaml', save_dir / 'evolve.csv'
if opt.bucket:
os.system(f'gsutil cp gs://{opt.bucket}/evolve.csv {save_dir}') # download evolve.csv if exists
for _ in range(opt.evolve): # generations to evolve
if evolve_csv.exists(): # if evolve.csv exists: select best hyps and mutate
# Select parent(s)
# 选择超参进化方式 只用single和weighted两种
parent = 'single' # parent selection method: 'single' or 'weighted'
x = np.loadtxt(evolve_csv, ndmin=2, delimiter=',', skiprows=1)
# 选取至多前五次进化的结果
n = min(5, len(x)) # number of previous results to consider
x = x[np.argsort(-fitness(x))][:n] # top n mutations
# 根据resluts计算hyp权重
w = fitness(x) - fitness(x).min() + 1E-6 # weights (sum > 0)
# 根据不同进化方式获得base hyp
if parent == 'single' or len(x) == 1:
# x = x[random.randint(0, n - 1)] # random selection
x = x[random.choices(range(n), weights=w)[0]] # weighted selection
elif parent == 'weighted':
x = (x * w.reshape(n, 1)).sum(0) / w.sum() # weighted combination
# Mutate 超参进化
mp, s = 0.8, 0.2 # mutation probability, sigma
npr = np.random
npr.seed(int(time.time()))
# 获取突变初始值
g = np.array([meta[k][0] for k in hyp.keys()]) # gains 0-1
ng = len(meta)
v = np.ones(ng)
# 设置突变
while all(v == 1): # mutate until a change occurs (prevent duplicates)
v = (g * (npr.random(ng) < mp) * npr.randn(ng) * npr.random() * s + 1).clip(0.3, 3.0)
# 将突变添加到base hyp上
for i, k in enumerate(hyp.keys()): # plt.hist(v.ravel(), 300)
hyp[k] = float(x[i + 7] * v[i]) # mutate
# Constrain to limits
for k, v in meta.items():
hyp[k] = max(hyp[k], v[1]) # lower limit
hyp[k] = min(hyp[k], v[2]) # upper limit
hyp[k] = round(hyp[k], 5) # significant digits
# 训练 使用突变后的参超 测试其效果
results = train(hyp.copy(), opt, device, callbacks)
# Write mutation results
print_mutation(results, hyp.copy(), save_dir, opt.bucket)
# Plot results
plot_evolve(evolve_csv)
print(f'Hyperparameter evolution finished\n'
f"Results saved to {colorstr('bold', save_dir)}\n"
f'Use best hyperparameters example: $ python train.py --hyp {evolve_yaml}')
遗传进化算法,边进化边训练。
使用遗传算法进行参数进化,默认是进化三百代。此处的进化算法是:根据之前训练时的base hyp再进行突变;
通过之前每次进化得到的results来确定之前每个hyp的权重
有了每个hyp和每个hyp的权重之后有两种进化方式:
1.根据每个htp的权重随机算则一个之前的hyp作为base hyp,random.choices(range(n),weights=w)
2.根据每个hyp的权重对之前所有的hyp进行融合获得一个base hyp, (x*w.reshape(n,1)).sum(0)/w.sum()
evolve.txt会记录每次进化之后的results进行从大到小的排序;
在根据fitness函数计算之前每次进化的到的hyp的权重,再确定哪一种进化方式,从而进行进化
分享 系统已结题
4月27日
系统已结题
4月27日 已采纳回答
4月19日
创建了问题
4月15日
已采纳回答
4月19日
创建了问题
4月15日

