




在做想关项目,因为需要自己的数据集,因此我按照要求做了一个,如下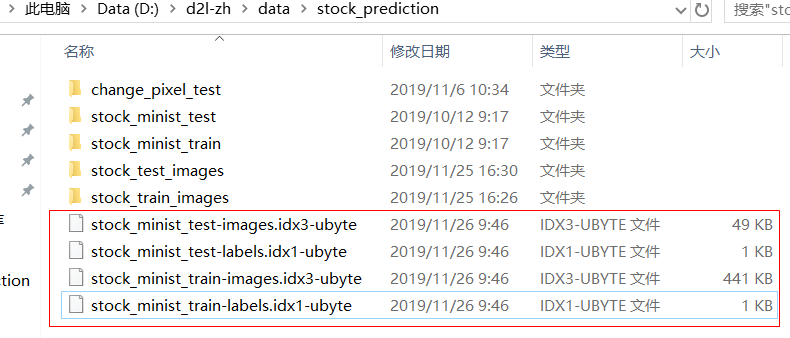
用的是MXNet框架,jupyter notebook写
我自己的做法是把测试集和训练集用数组读取后包装
训练集如下,两个数组分别是图片像素和对应标签
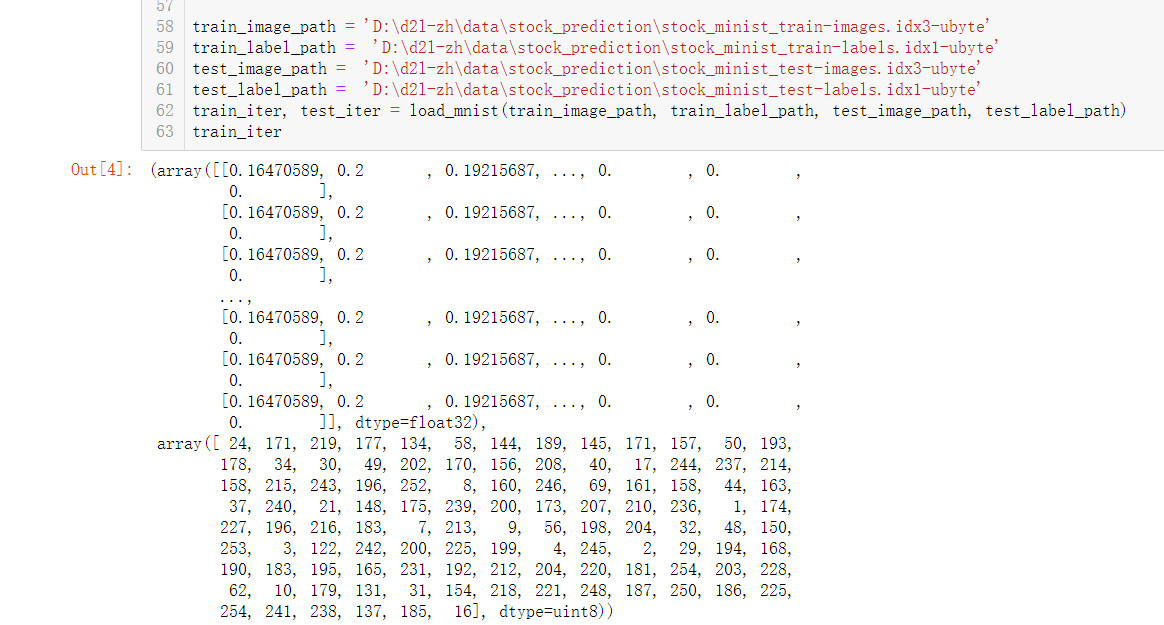
训练过程如下,为了能分别遍历又拆了train_iter为train_iter[0]、[1]
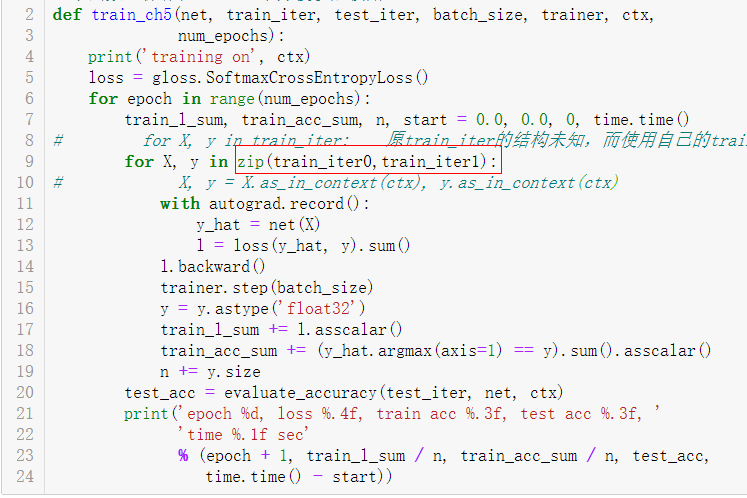
接着在导入训练模型(第12行)时候出现问题,报错如下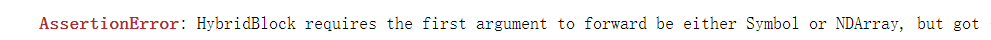
搞了几天不明白这个数据类型,是导入数据集的方式错了还是、、、、
下面这个是载入Fashion-MNIST数据集的函数
没看明白,现在还在尝试,但是有大佬指导下就更好了(求~)

附代码
def load_data_fashion_mnist(batch_size, resize=None, root=os.path.join(
'~', '.mxnet', 'datasets', 'fashion-mnist')):
root = os.path.expanduser(root) # 展开用户路径'~'
transformer = []
if resize:
transformer += [gdata.vision.transforms.Resize(resize)]
transformer += [gdata.vision.transforms.ToTensor()]
transformer = gdata.vision.transforms.Compose(transformer)
mnist_train = gdata.vision.FashionMNIST(root=root, train=True)
mnist_test = gdata.vision.FashionMNIST(root=root, train=False)
num_workers = 0 if sys.platform.startswith('win32') else 4
train_iter = gdata.DataLoader(
mnist_train.transform_first(transformer), batch_size, shuffle=True,
num_workers=num_workers)
test_iter = gdata.DataLoader(
mnist_test.transform_first(transformer), batch_size, shuffle=False,
num_workers=num_workers)
return train_iter, test_iter
batch_size = 128
# 如出现“out of memory”的报错信息,可减小batch_size或resize
train_iter, test_iter = load_data_fashion_mnist(batch_size, resize=224)




























