在利用卷积神经网络训练一组数据时,损失值从3.7左右下降到0.15左右,之后损失值不再下降,这种情况是否可以认为已经收敛?但此时的测试集准确率只有92%左右,如果想要继续提高准确率,应该从哪方面入手:数据集本身?网络模型?训练参数?还是其它方面?
这是训练的两张图: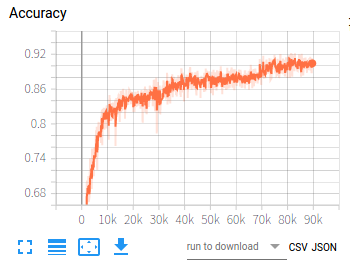
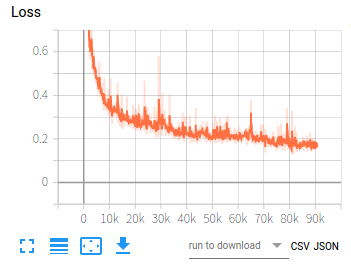

神经网络训练时,损失值在0.1波动,不再下降,是否认为已经收敛?

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

1条回答 默认 最新
 threenewbee 2020-01-09 11:41关注
threenewbee 2020-01-09 11:41关注一个是本身数据的可学习性,一个是模型的问题。一个是网络调参不好。
打一个比方,如果仅仅用每天的天气数据预测每天的股票价格,怎么预测都误差很大,这个就是可学习性差。可学习性差表现为过拟合。
而用一个只有单层10个神经元的网络去判别图片,这个就是模型的问题。模型不好主要表现在学不动,不收敛。
还有一个就是网络调参,比如说虽然你的网络复杂性够了,数据也OK,但是优化器不好,导致梯度消失,过早收敛,这个你要换优化器的算法,必要的时候可以用网格搜索的方式手动调参。评论 打赏解决 5无用 2举报 分享
- 2024-10-10 20:42Jack_pirate的博客 对数据扩增也能够实现正则化的效果,最好的...在自己训练新网络时,可以从0.1开始尝试,如果loss不下降的意思,那就降低,除以10,用0.01尝试,一般来说0.01会收敛,不行的话就用0.001. 学习率设置过大,很容易震荡。
- 2024-04-27 10:58小白学视觉的博客 第一时间送达作者丨风影忍着@知乎(已授权)来源丨https://zhuanlan.zhihu.com/p/285601835编辑丨极市平台极市导读本文从数据与标签、模型以及...状况三个大方面去总结了神经网络训练过程中不收敛或者训练失败的原因...
- 2025-04-18 17:47谦亨有终的博客 在小批量梯度下降法中,批量大小(Batch Size)对网络优化的影响也非常大,本文我们来学习如何选择小批量梯度下降的批量大小。
- 2025-04-14 16:02AI拉呱-洞察AI技术前沿的博客 如果只是validate set上不收敛那就说明...在自己训练新网络时,可以从0.1开始尝试,如果loss不下降的意思,那就降低,除以10,用0.01尝试,一般来说0.01会收敛,不行的话就用0.001. 学习率设置过大,很容易震荡。
- 2023-11-27 12:48TwcatL的博客 在面对模型不收敛的时候,首先要保证训练的次数够多。在训练过程中,loss并不是一直在下降,准确率一直在提升的,会有一些震荡存在。train loss 不断上升,test loss不断上升,说明网络结构设计不当,训练超参数设置...
- 2020-12-06 00:21weixin_39795116的博客 点击蓝字关注我们AI研习图书馆,发现不一样的世界炼丹笔记深度学习炼丹笔记二深度学习模型训练技巧及可能出现的问题分析1、导致模型训练不收敛的原因有哪些?一、数据和标签实验数据分类或标注是否准确?数据是否...
- 2025-04-28 10:00Sylvan Ding的博客 本文将带您踏上一场优化器世界的探索之旅,从基础的随机梯度下降(SGD)出发,逐一解析 Momentum、AdaGrad、RMSprop、Adam、Nadam、AdamW、RAdam 等主流优化算法的核心思想、更新过程和实际应用。无论您是深度学习...
- 2020-11-19 20:04weixin_39866419的博客 几周前,我在发了一条”最常见的神经网络错误”的微博(•̀ᴗ•́)و ̑̑ ,列举了一些与训练神经网络相关的常见错误,这条微博引发了大家热烈的讨论。相信很多人都曾亲身经历过”卷积层的工作原理”和”训练的实际...
- 2025-08-05 20:42光子AI的博客 本文将带你跳出“孤立数据”的陷阱,系统讲解如何构建一个基于图神经网络(GNN)的智能营销AI平台。我们会从营销场景的本质需求出发,解析GNN如何解决传统模型的局限性,详细拆解平台的架构设计、数据建模、核心算法...
- 2025-08-25 17:51无心水的博客 随后详解梯度下降算法家族,包括精准但缓慢的批量梯度下降、快速但波动的随机梯度下降,以及平衡二者的迷你批量梯度下降。通过Mermaid图表直观展示损失函数地形特征,并结合代码实例演示优化算法的具体实现。摘要...
- 没有解决我的问题, 去提问
