
def BP_Net(x, y, lr=0.01, hidden=20, loop=2000):
X = tf.compat.v1.placeholder(tf.float32, [None, 1])
Y = tf.compat.v1.placeholder(tf.float32, [None, 1])
# 输入层到隐藏层
W1 = tf.compat.v1.Variable(tf.compat.v1.random_normal([1, hidden]))
B1 = tf.compat.v1.Variable(tf.compat.v1.zeros([1, hidden]))
L1 = tf.compat.v1.nn.tanh(tf.matmul(X, W1) + B1)
# 隐藏层到输出层
W2 = tf.compat.v1.Variable(tf.compat.v1.random_normal([hidden, 1]))
B2 = tf.compat.v1.Variable(tf.compat.v1.zeros([1, 1]))
L2 = tf.matmul(L1, W2) + B2
# 二次代价函数
loss = tf.reduce_mean(tf.square(Y - L2))
# 梯度下降法
train_step = tf.compat.v1.train.GradientDescentOptimizer(lr).minimize(loss)
with tf.compat.v1.Session() as sess:
sess.run(tf.compat.v1.global_variables_initializer())
for i in range(loop):
sess.run(train_step, feed_dict={X: x, Y: y})
loss1 = sess.run(loss, feed_dict={X: x, Y: y})
print(f"loss:{loss1}")
predict = sess.run(L2, feed_dict={X: x})
print(f"predict:{predict}")
picture(x, y, predict)
def picture(x, y, predict):
plt.figure()
plt.plot(x, y, label="原始数据")
plt.plot(x, predict, label="预测数据")
plt.legend()
plt.show()
if __name__ == "__main__":
X = np.array(list(np.arange(19, 20, 0.01))).reshape([-1, 1])
Y = (X * X + 1).reshape([-1, 1])
# 归一化
# min_max_scaler = MinMaxScaler()
# Y = min_max_scaler.fit_transform(Y)
BP_Net(X, Y, lr=0.001, hidden=20, loop=4000)
像X这种数据变化较小,用BP神经网络怎么调参数都不行,都不能拟合
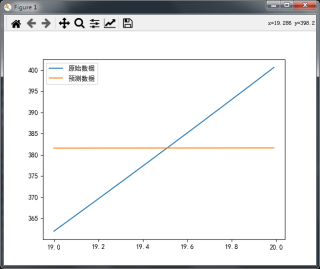
这种情况怎么办?





