
毕设导师 要求用paddle进行文本分类,先输入文本经过几层神经网络后,加上之前额外提取的文本特征以及经过神经网络输出的文本 作为下一个全连接层的输入,初学paddle,还有很多不懂的地方,在训练的时候碰到的报错
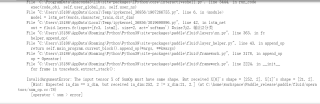
知道是维度的问题,但是不知道怎么查看具体的数据维度
这是输入的数据(分别是文本、标签、12个特征):

以下是构建的神经网络:
def lstm_net(ipt, x,input_dim):
# 以数据的IDs作为输入
print("-----------------我在lstm_net---------------------------")
print("input_dim",input_dim)
emb = fluid.layers.embedding(input=ipt, size=[input_dim, 128], is_sparse=True)
print("emb",emb)
# 第一个全连接层
fc1 = fluid.layers.fc(input=emb, size=128)
print("fc1",fc1)
# 进行一个长短期记忆操作
lstm1, _ = fluid.layers.dynamic_lstm(input=fc1, #返回:隐藏状态(hidden state),LSTM的神经元状态
size=128) #size=4*hidden_size
# 第一个最大序列池操作
fc2 = fluid.layers.sequence_pool(input=fc1, pool_type='max')
print("我这里是在定义长短期记忆网络lstm_net里,我在输出fc2",fc2)
# 第二个最大序列池操作
lstm2 = fluid.layers.sequence_pool(input=lstm1, pool_type='max')
print("我这里是在定义长短期记忆网络lstm_net里,我在输出lstm2",lstm2)
# 以softmax作为全连接的输出层,大小为2,也就是正负面
# out = fluid.layers.fc(input=[fc2, lstm2], size=2, act='softmax') #size为2,输出2分类 这一层输出层删除
#全连接层1
fc3 = fluid.layers.fc(input=x , size=12,act=None) #x 就是额外的特征
print("我这里是在定义长短期记忆网络lstm_net里,我在输出fc3",fc3)
全连接层2
fc4 = fluid.layers.fc(input =[fc3,fc2], size=128 ,act=None)
print("我这里是在定义长短期记忆网络lstm_net里,我在输出fc4",fc4)
最后输出二分类 softmax
out = fluid.layers.fc(input=[fc2,lstm2], size=2, act='softmax') #size为2,输出2分类
print(out)
return out
定义数据层以及获取分类器:
paddle.enable_static() #不输入就会报错
# 定义输入数据, lod_level不为0指定输入数据为序列数据
words = fluid.data(name='words', shape=[None,1], dtype='int64', lod_level=1)
# print(type(character_train_list[1][1]))
character_train=fluid.data(name='character_train', shape=[None,1], dtype='float32', lod_level=1)
label = fluid.data(name='label', shape=[None,1], dtype='int64')
# 获取数据字典长度
dict_dim = get_dict_len(dict_path)
print("!!",dict_dim)
# 获取分类器
model = lstm_net(words,character_train,dict_dim)
正式训练:
EPOCH_NUM=10 #训练轮数
model_save_dir = 'C:/Users/15186/Desktop/谣言2/infer_model/' #模型保存路径
data_character=[]
for (ida,i),(idb,j) in zip(enumerate(character_train_reader()),enumerate(train_reader())):
temp_a = list(i[ida])
temp_b = list(j[idb])
temp_b.append(temp_a)
# print(temp_b)
data_character.append(tuple(temp_b))
# print("++++++++++++++++++++++++++")
print(data_character)
# 开始训练
for pass_id in range(EPOCH_NUM):
# 进行训练
# print("pass_id",pass_id)
for batch_id, data in enumerate(train_reader()): #enumerate函数可以把一个list变成索引-元素对(也是在迭代)
# print(batch_id)
print("#################################################")
train_cost, train_acc = exe.run(program=fluid.default_main_program(),
feed=feeder.feed(data_character), #这里是往网络里面喂数据
fetch_list=[avg_cost, acc])
all_train_iter=all_train_iter+BATCH_SIZE
all_train_iters.append(all_train_iter)
all_train_costs.append(train_cost[0])
all_train_accs.append(train_acc[0])
if batch_id % 100 == 0:
print('Pass:%d, Batch:%d, Cost:%0.5f, Acc:%0.5f' % (pass_id, batch_id, train_cost[0], train_acc[0]))
# 保存模型
if not os.path.exists(model_save_dir):
os.makedirs(model_save_dir)
fluid.io.save_inference_model(model_save_dir,
feeded_var_names=[words.name],
target_vars=[model],
executor=exe)
print('训练模型保存完成!')
draw_process("train",all_train_iters,all_train_costs,all_train_accs,"trainning cost","trainning acc")
draw_process("eval",all_eval_iters,all_eval_costs,all_eval_accs,"evaling cost","evaling acc")






