
自实现的vgg11网络与torch自带的vgg11 训练结果为什么不同?
最近学习了一下vgg网络, 于是,自己按照文档自实现一个vgg网络, 使用flower_photos数据集(关于此数据集介绍,可参考此文章: https://blog.csdn.net/Serendipity_zyx/article/details/124740035 )进行训练, 此数据集有5种分类, 每个分类最小不小于600张照片。 我把5个分类的照片前500张设置train, 接下来100张图片设置为valid, 剩下的作为最终测试所用。
下面是我自搭建的网络:
import torch
import torchvision
from torch import nn
from torchvision import transforms as T
from torchvision.datasets import ImageFolder
import torch.utils.data
import torch.optim as optim
## vgg11网络
class Vgg11(nn.Module):
def __init__(self, num_classes = 5):
super(Vgg11, self).__init__()
torch._C._log_api_usage_once('python.nn_module')
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=(3,3), stride=(1,1), padding=(1,1)), #224*224
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False), #112*112
nn.Conv2d(64, 128, kernel_size=(3,3), stride=(1,1), padding=(1,1)), #112*112
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False), #56*56
nn.Conv2d(128, 256, kernel_size=(3,3), stride=(1,1), padding=(1,1)), #56*56
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=(3,3), stride=(1,1), padding=(1,1)), #56*56
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False), #28*28
nn.Conv2d(256, 512, kernel_size=(3,3), stride=(1,1), padding=(1,1)), #28*28
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=(3,3), stride=(1,1), padding=(1,1)), #28*28
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False), #14*14
nn.Conv2d(512,512, kernel_size=(3,3), stride=(1,1), padding=(1,1)), #14*14
nn.ReLU(inplace=True),
nn.Conv2d(512,512, kernel_size=(3,3), stride=(1,1), padding=(1,1)), #14*14
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) #7*7
)
self.avgPool = nn.AdaptiveMaxPool2d(output_size=(7, 7))
self.classifier = nn.Sequential(
nn.Linear(512*7*7, 4096),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(4096, num_classes)
)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode = 'fan_out', nonlinearity = 'relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.features(x)
x = self.avgPool(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
DEVICE = torch.device('cuda'if torch.cuda.is_available() else 'cpu') # cpu or cuda
EPOCH = 20
BATCH_SIZE = 100
## train 数据集预处理
train_path = 'F:/ml-data/flower_photos/train'
train_trans = T.Compose([
T.RandomResizedCrop(size = 256, scale=(0.8, 1.0)),
T.CenterCrop(size = 224),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225])
])
train_set = ImageFolder(root=train_path, transform=train_trans)
train_len = len(train_set)
print(f'train_len: {train_len}')
train_loader = torch.utils.data.DataLoader(train_set, batch_size=BATCH_SIZE, shuffle = True, num_workers=0)
idx_to_class = {v:k for k, v in train_set.class_to_idx.items()} ## 获取id与分类对应关系
print(idx_to_class)
## test 数据集预处理
test_path = 'F:/ml-data/flower_photos/test'
test_trans = T.Compose([
T.Resize(size=256),
T.CenterCrop(size=224),
T.ToTensor(),
T.Normalize(mean=[0.485, .0456, 0.406], std = [0.229, 0.224, 0.225])
])
test_set = ImageFolder(root=test_path, transform=test_trans)
test_len = len(test_set)
print(f'test_len: {test_len}')
test_loader = torch.utils.data.DataLoader(test_set, batch_size=BATCH_SIZE, shuffle= True, num_workers=0)
## valid 数据集预处理
valid_path = 'F:/ml-data/flower_photos/valid'
valid_trans = T.Compose([
T.Resize(size=256),
T.CenterCrop(size=224),
T.ToTensor(),
T.Normalize(mean=[0.485, .0456, 0.406], std = [0.229, 0.224, 0.225])
])
valid_set = ImageFolder(root=valid_path, transform=valid_trans)
valid_len = len(valid_set)
print(f'valid_len: {valid_len}')
valid_loader = torch.utils.data.DataLoader(valid_set, batch_size=BATCH_SIZE, shuffle=True, num_workers=0)
## 训练过程
def train_and_validate(model, loss_criterion, optimizer):
history = [] #记录历史数据
best_loss = 100000.0
best_epoch = None
for epoch in range(EPOCH):
print(f'Epoch: {epoch + 1}/{EPOCH}')
model.train()
train_acc = 0.0
valid_acc = 0.0
train_loss = 0.0
valid_loss = 0.0
for i, (inputs, labels) in enumerate(train_loader):
inputs = inputs.to(DEVICE)
labels = labels.to(DEVICE)
optimizer.zero_grad() # 消除梯度
outputs = model(inputs)
loss = loss_criterion(outputs, labels) #计算损失
loss.backward() # 后向传播
optimizer.step() # 更新参数
train_loss += loss.item() * inputs.size(0) # 计算这次训练总损失量,并加入train_loss
ret, predictions = torch.max(outputs.data, dim = 1)
correct_counts = predictions.eq(labels.data.view_as(predictions)) #计算准确数
acc = torch.mean(correct_counts.type(torch.FloatTensor)) # 每一项的准确数求平均值
train_acc += acc.item() * inputs.size(0)
print("Batch number: {:03d}, Training: Loss: {:.4f}, Accuracy: {:.4f}".format(i, loss.item(), acc.item()))
with torch.no_grad(): ## 验证 不需要梯度跟踪
model.eval() # 设置eval模式
for j , (inputs, labels) in enumerate(valid_loader):
inputs = inputs.to(DEVICE)
labels = labels.to(DEVICE)
outputs = model(inputs)
loss = loss_criterion(outputs, labels)
valid_loss += loss.item() * inputs.size(0)
ret, predictions = torch.max(outputs.data, dim = 1)
correct_counts = predictions.eq(labels.data.view_as(predictions))
acc = torch.mean(correct_counts.type(torch.FloatTensor))
valid_acc += acc.item() * inputs.size(0)
print("Validation Batch number: {:03d}, Validation: Loss: {:.4f}, Accuracy: {:.4f}".format(j, loss.item(), acc.item()))
if valid_acc < best_loss:
best_loss = valid_loss
best_epoch = epoch
avg_train_loss = train_loss/train_len
avg_valid_loss = valid_loss/valid_len
avg_train_acc = train_acc/train_len
avg_valid_acc = valid_acc/valid_len
history.append([avg_train_loss, avg_valid_loss, avg_train_acc, avg_valid_acc])
print("Epoch : {:03d}, Training: Loss - {:.4f}, Accuracy - {:.4f}%, \n\t\tValidation : Loss - {:.4f}, Accuracy - {:.4f}%".format(epoch, avg_train_loss, avg_train_acc*100, avg_valid_loss, avg_valid_acc*100))
#torch.save(model, dataset + '_model_' + str(epoch) + '.pt') ## 保存模型
return model, history, best_epoch
model = Vgg11().to(DEVICE)
loss_func = nn.CrossEntropyLoss() # 损失函数
#optimizer = optim.SGD(params=model.parameters(), lr = 0.01, momentum=0.9, weight_decay=0.0005)
optimizer = optim.Adam(params=model.parameters(), lr = 0.001)
trained_model, history, best_epoch = train_and_validate(model, loss_func, optimizer)
history = np.array(history)
history
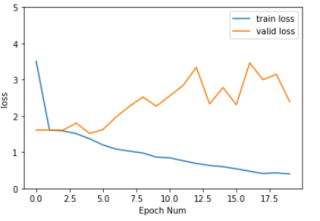
array([[3.5052902 , 1.60807209, 0.1952 , 0.198 ],
[1.60560584, 1.61016963, 0.2328 , 0.2 ],
[1.58769461, 1.60636456, 0.236 , 0.2 ],
[1.51167903, 1.8029999 , 0.3032 , 0.22399999],
[1.37022757, 1.51605713, 0.3676 , 0.37000001],
[1.19959129, 1.62299871, 0.4868 , 0.302 ],
[1.08311709, 1.97506301, 0.5616 , 0.266 ],
[1.02850691, 2.26851072, 0.5772 , 0.22800001],
[0.97669484, 2.52203932, 0.6132 , 0.22 ],
[0.8644706 , 2.26841426, 0.6696 , 0.25 ],
[0.84407005, 2.55108919, 0.672 , 0.258 ],
[0.76348852, 2.83528318, 0.70080001, 0.258 ],
[0.68927675, 3.34105282, 0.7492 , 0.246 ],
[0.63422104, 2.32937741, 0.7544 , 0.26599999],
[0.59926847, 2.78308396, 0.7728 , 0.262 ],
[0.54071707, 2.30894341, 0.8068 , 0.316 ],
[0.47304197, 3.46418118, 0.8208 , 0.252 ],
[0.41170241, 2.99827628, 0.8488 , 0.29 ],
[0.42943882, 3.14858818, 0.8392 , 0.336 ],
[0.39788979, 2.3907634 , 0.8572 , 0.404 ]])
plt.plot(history[:,0:2])
plt.legend(['train loss', 'valid loss'])
plt.xlabel('Epoch Num')
plt.ylabel('loss')
plt.ylim(0, 5)
plt.show()
plt.plot(history[:, 2:])
plt.legend(['train acc', 'valid acc'])
plt.xlabel('Epoch Num')
plt.ylabel('acc')
plt.ylim(0,1)
plt.show()
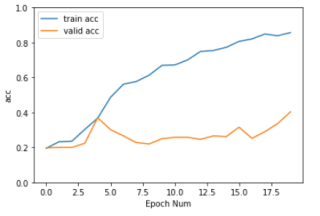
训练过程中效率缓慢, 每轮训练结果改进不大, 过拟合现像明显。 训练结果非常不理想。。
于是使用torch自带的vgg11与之对比
使用torch 的vgg11的:
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
vgg11 = torchvision.models.vgg11(pretrained=True)
vgg11 = vgg11.to(device)
for param in vgg11.parameters():
param.requires_grad = False ## 屏蔽预训练权重
vgg11.classifier = nn.Sequential( ## 重新定义classifier
nn.Linear(512*7*7, 4096),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(4096, 5)
)
其它的一切都一样, 同样的训练数据, 同样的训练过程。 损失函数, 优化器等等全都一样, 但结果却相差很大。
history = np.array(history)
history
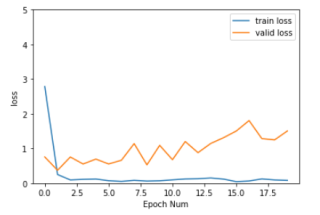
array([[2.78441757, 0.75438148, 0.63839999, 0.71 ],
[0.24754931, 0.3692995 , 0.9172 , 0.86199999],
[0.0917752 , 0.75352796, 0.97040001, 0.778 ],
[0.1081206 , 0.55052951, 0.97080001, 0.838 ],
[0.11770987, 0.69296242, 0.96920001, 0.798 ],
[0.06948721, 0.55145215, 0.97760001, 0.81799998],
[0.05022513, 0.65891484, 0.98600001, 0.824 ],
[0.07993821, 1.13849299, 0.98160001, 0.75 ],
[0.05927692, 0.52662418, 0.98200001, 0.85600002],
[0.06743618, 1.08958749, 0.98280001, 0.77199999],
[0.09404423, 0.67531353, 0.97600001, 0.854 ],
[0.11961563, 1.19895799, 0.97680001, 0.77999998],
[0.12658107, 0.87833561, 0.97200001, 0.82199999],
[0.14860773, 1.1438055 , 0.97240001, 0.80399998],
[0.11542095, 1.30981824, 0.98160001, 0.774 ],
[0.0428307 , 1.50262409, 0.98560001, 0.78000001],
[0.06157512, 1.80351961, 0.98760001, 0.736 ],
[0.12065221, 1.28342099, 0.97960001, 0.81799999],
[0.09147686, 1.24664183, 0.98480001, 0.82400001],
[0.07923115, 1.50392275, 0.98400001, 0.788 ]])
plt.plot(history[:,0:2])
plt.legend(['train loss', 'valid loss'])
plt.xlabel('Epoch Num')
plt.ylabel('loss')
plt.ylim(0, 5)
plt.show()
plt.plot(history[:, 2:])
plt.legend(['train acc', 'valid acc'])
plt.xlabel('Epoch Num')
plt.ylabel('acc')
plt.ylim(0,1)
plt.show()
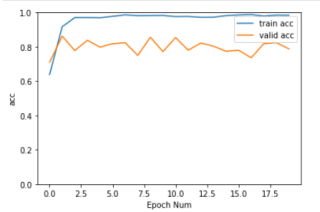
训练结果也出现过拟合现像, 但无疑 结果比自实现网络好多了。
于是我仔细查看了vgg网络实现的源代码, 发现逻辑上与自实现的并无差别, 不知道为什么训练结果相差这么大?







