我运用机器学习的方法来预测两个蛋白质是否互作,而目前有4种基于氨基酸序列的编码方法结合SVM构成4种预测方法。我参考了别人的文献用下面的公式对4种方法进行一个整合,希望整合后能够比单种预测方法的预测精度要高。
每一个样本运用的公式如下: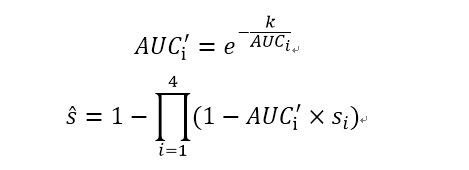
这里的s_i指的是每个样本用第i种方法预测后的得分,〖AUC〗_i指的是所有样本用第i种预测方法预测后的得分做出ROC曲线下的面积,s ̂为整合后每个样本的分数。
我不明白的地方是,这两个公式背后到底蕴含着什么意义和道理,为何要这样进行处理?

机器学习中整合不同预测方法的公式的含义

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


1条回答 默认 最新

- 回答 1 已采纳 分割数据集到训练集和测试集 x_train, x_test, y_train, y_test = train_test_split(x, y) 你加载模型直接预测 不需要对数据进行再
- 2019-04-28 20:32回答 2 已采纳 可以进行多目标,比如在回归问题中,决策树和神经网络就可以同时预测多个目标值。 可以参考论文,A survey on multi‐output regression
- 2022-06-01 10:23回答 1 已采纳 import pandas as pd import re import numpy as np from sklearn.ensemble import RandomForestRegressor
- 2023-06-23 00:01hellenionia的博客 后续结合验证集作用时,会选出同一参数的不同取值,拟合出多个分类器。验证集(Cross Validation set)作用是当通过训练集训练出多个模型后,为了能找出效果最佳的模型,使用各个模型对验证集数据进行预测,并记录模型...
- 2022-10-20 01:39回答 1 已采纳 问题是不一定有未知的数据去让你当预测集 所以才把原始数据划分为测试集与训练集 预测出来后与测试集进行对比看预测效果
- 2023-02-08 21:05回答 3 已采纳 估计集是机器学习中用来估计模型参数的样本集,其中每个样本都有一个与之相关联的标签。估计集与其他样本集的关系是,估计集用来估计模型参数,而其他样本集用来测试模型的性能好坏。
- 2022-04-29 09:25回答 2 已采纳 选特征,打标签,调sklearn 包训练,预测,结束
- 2023-06-04 22:10鹿港小小镇的博客 本研究探索了一系列监督机器学习算法来估计水质指数(WQI)和水质类(WQC),水质指数是描述水的一般质量的奇异指标,水质类是在WQI的基础上定义的独特类。所提出的方法采用四个输入参数,即温度(temperature)浊度...
- 2022-07-14 11:31回答 1 已采纳 公式只是公式,矩阵相乘看数据格式啊,公式只是说明,一般来说在机器学习里面如果没有特殊说明,y=XW+B 和 y=WX+B 在神经网络中是等价的,(不要和线代里面的矩阵乘法不能交换位置混掉),这两个意思
- 2022-12-27 13:23回答 2 已采纳 检查一下你传进去的参数x_triain,y_triain,这是字符串类型,当然没有loc了,应该是DataFrame
- 2019-11-07 07:01回答 1 已采纳 首先,不建议这么做,如果把train和test都用来训练,没测试集来看效果。 如果真要这么做,可以在训练前先把两个文件合并再投入训练
- 2023-12-31 01:10禅与计算机程序设计艺术的博客 随着计算能力的提高和数据量的增加,机器学习技术在物料科学中发挥了越来越重要的作用。机器学习可以帮助物料科学家预测材料性能,优化材料结构,提高材料性能,降低研发成本,加快新材料的研发进程。 在过去的几年...
- 2020-02-21 18:37回答 2 已采纳 ``` X.T * y - X.T * X * theta = 0 //蓝线公式打开括号,去掉常数项 X.T
- 2022-02-22 16:47louwill12的博客 大家好!我是louwill。年前说要为《机器学习 公式推导与代码实现》一书配套随书的PPT,过年期间断断续续做了一些工作,目前初步完成了几章内容的PPT,先发一章示例给大家,希望大家多提一...
- 2024-01-18 02:04禅与计算机程序设计艺术的博客 在大数据时代,Elasticsearch在搜索、分析和机器学习等领域发挥了广泛的应用。本文将从以下几个方面进行阐述: 背景介绍 核心概念与联系 核心算法原理和具体操作步骤以及数学模型公式详细讲解 具体代码实例和详细...
- 没有解决我的问题, 去提问


悬赏问题
- ¥15 stata安慰剂检验作图但是真实值不出现在图上
- ¥15 c程序不知道为什么得不到结果
- ¥40 复杂的限制性的商函数处理
- ¥15 程序不包含适用于入口点的静态Main方法
- ¥15 素材场景中光线烘焙后灯光失效
- ¥15 请教一下各位,为什么我这个没有实现模拟点击
- ¥15 执行 virtuoso 命令后,界面没有,cadence 启动不起来
- ¥50 comfyui下连接animatediff节点生成视频质量非常差的原因
- ¥20 有关区间dp的问题求解
- ¥15 多电路系统共用电源的串扰问题