在学习Word2Vec的时候
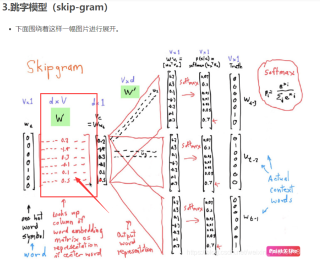
会使用到一层embedding 层来使中心词的ont-hot 矩阵降维,但是我想知道 这个embedding layer里面的这个embedding 矩阵是根据什么来生成的呢? 有什么论文或者谁能解释一下原理么?

在学习Word2Vec的时候
 分享
分享 分享
分享 感谢! 那这样我还有一个问题,就是这个“embedding层的查找表”又是如何初始化生成的呢? 因为最开始总得有一个初始化的表才能用BP算法更新这个表吧
这个可以看一看 embedding 层的 python 包装,其中的 .weight 就是查找表,事实上就是通过一个中心为 0,方差为 1 的正态分布随机取样的。还望采纳答案。
可以看 embedding 的实现,我怀疑初始化的过程不同框架可能不一样,在 pytorch 中就是简单的用中心为 0,方差为 1 的正态分布随机采样得到的初始参数。答案还望采纳。
 系统已结题
8月5日
系统已结题
8月5日 已采纳回答
7月29日
创建了问题
7月20日
已采纳回答
7月29日
创建了问题
7月20日











