
请问可以分享一下pytorch版的基于CNN的轴承故障诊断的源码嘛?我整了好久,处处都是问题,也不知道哪错了,我想学一下这个案例,求分享
我感觉我这个问题好像出在了输入维度那里,但是不这个维度的话会报错,计算出的output长这个样子
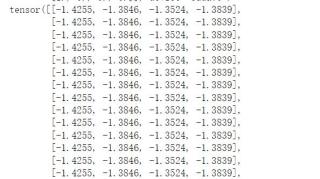
```python
class WDCNN(nn.Module):
def __init__(self):
super().__init__()
# 输入1*2048*1
self.layer1 = nn.Sequential(
nn.Conv2d(
in_channels=1,
out_channels=16,
kernel_size=(64, 1),
stride=16,
padding=24,
), # 16*128*1
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 1), stride=(2)), # 16*64*1
)
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=(3, 1), stride=1, padding=1), # 32*64*1
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 1), stride=(2)), # 32*32*1
)
self.layer3 = nn.Sequential(
nn.Conv2d(32, 64, kernel_size=(3, 1), stride=1, padding=1), # 64*32*1
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 1), stride=(2)), # 64*16*1
)
self.layer4 = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=(3, 1), stride=1, padding=1), # 64*16*1
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 1), stride=(2)), # 64*8*1
)
self.layer5 = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=(3, 1), stride=1, padding=1), # 64*8*1
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 1), stride=(2)), # 64*4*1
)
self.fc = nn.Sequential(nn.Linear(512, 100), nn.ReLU(), nn.Linear(100, 4))
def forward(self, x):
# print(x.size())
x = self.layer1(x)
# print(x.size())
x = self.layer2(x)
# print(x.size())
x = self.layer3(x)
# print(x.size())
x = self.layer4(x)
# print(x.size())
x = self.layer5(x)
# print(x.size())
x = x.view(x.size(0), -1)
x = self.fc(x)
output = F.log_softmax(x, dim=1)
# print(output)
return output
epochs = 20 # 训练数据的轮次
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = WDCNN().to(device)
optimizer = optim.Adam(model.parameters())
train_X = train_X.reshape([5600, 1, 2048, 1])
valid_X = valid_X.reshape([1600, 1, 2048, 1])
test_X = test_X.reshape([800, 1, 2048, 1])
#训练
def train_model(model, device, train_X, optimizer, epoch):
# 模型训练
model.train()
batchs = np.split(train_X, 28) # 每批处理100个数据
for batch_index, data in enumerate(batchs):
# print(batch_index, data)
# print(data.size())
target = train_Y[batch_index * 200 : batch_index * 200 + 200]
# print(target)
data = torch.tensor(data).to(device)
target = torch.tensor(target).to(device)
print(len(target))
# print(data.size())
print(data, target)
# 梯度初始化为0
optimizer.zero_grad()
# 训练结果
output = model(data).to(device)
print(output)
pred = output.argmax(dim=1)
print(pred)
# 计算损失 交叉熵损失(针对多分类问题)
loss = F.cross_entropy(output, target).to(device)
# print(loss)
# 反向传播
loss.backward()
# 参数更新
optimizer.step()
if batch_index % 100 == 0:
print("Train epoch:{} \t Loss:{:.6f}".format(epoch, loss.item()))
train_loss_list.append(loss.item())
```






