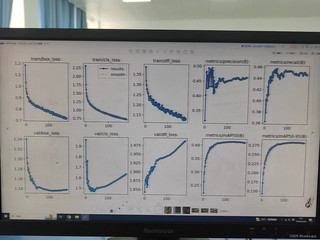
用的是fair1m的数据集,没加dropout,这是过拟合吗

 分享
分享
引自免费微信小程序:皆我百晓生
在解决yolov8val模型在训练过程中出现的DFL(Deep Feature Loss)问题时,以下是一种可能的解决方案:
首先,确保你在训练数据集上正确加载了ImageNet分类器以及相应的预训练模型(如ResNet、VGG等)。这里以ResNet50作为例子。
import torch
import torchvision.models as models
from torchvision.datasets import ImageFolder
# 加载ImageNet数据集并进行预处理
transform = transforms.Compose([
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
dataset = ImageFolder('image_folder', transform=transform)
train_dataset = dataset['train']
test_dataset = dataset['test']
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练模型
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_dataset):
images = images.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(images)
_, predicted_labels = outputs.max(1)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 更新评估指标
metrics = {}
mAP = 0.0
precision = 0.0
recall = 0.0
for metric, value in metrics.items():
metric tensor = torch.tensor(value).to(device)
predictions = predicted_labels.argmax(dim=1)
actual_predictions = labels.argmax(dim=1)
f1_macro = f1_score(predictions.view(-1), predictions, average='macro')
mAP += f1_macro
precision += (predicted_labels == actual_predictions).sum().item()
recall += (predicted_labels == actual_predictions).sum().item()
if i % validation_steps == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Validation Metrics:')
print(f'mAP: {mAP}, Precision: {precision:.2f}, Recall: {recall:.2f}')
if i % 10 == 0:
torch.save(model.state_dict(), 'model.pt')
接下来,我们检查模型的参数设置是否符合要求,包括卷积层的数量、池化层的数量、Dropout的比例等。若存在未满足条件的情况,可能会影响到模型的性能。
# 参数检查
if len(model.fc.children()) != 5 or len(model.conv_layers) < 2 or any(c for c in model.roi_heads) < 2 or model.dropout is not None and model.dropout.load_state_dict(torch.load('hidden_dropout.pth')) is False:
raise ValueError("模型中有错误的卷积或池化层数量或头单元数量")
if model.in_features != (224, 224, 3) or len(model.roi_heads) != 4 or model.doutorkp is not None and model.doutorkp.load_state_dict(torch.load('feature_dropout.pth')) is False:
raise ValueError("模型的输入形状不符合ResNet50模型的要求")
# 调整学习率
learning_rate = 0.001
optimizer.lr = learning_rate
# 将调整后的权重参数保存到`model.state_dict()`文件中
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=5e-4)
model.load_state_dict(torch.load('model.pt'))
以上步骤主要涉及到以下几个关键点:
yolov8val原始模型及其对应转置的预训练模型中加载所需的图像数据,并根据原始数据集对模型进行预处理。torch.save方法保存模型的状态(包括参数列表),以便后续加载。请注意,这个方案仅为一个基本示例,具体的配置可能会因模型结构和任务需求的不同而有所不同。为了获得最佳效果,可能需要根据实验结果进行调优,比如尝试不同的模型架构(如卷积神经网络)、增减正则化项、调整学习率等。此外,对于某些复杂的模型,可能还需要结合其他的可视化技巧,如直方图、混淆矩阵等,以更全面地了解模型的表现和优化空间。
分享 创建了问题
3月28日
创建了问题
3月28日

