tensorflow模型,4层cnn
跑出来的结果训练集能达到1,测试集准确率基本保持在0.5左右,二分类
数据有用shuffle, 有dropout,有正则化,learning rate也挺小的。
不知道是什么原因,求解答!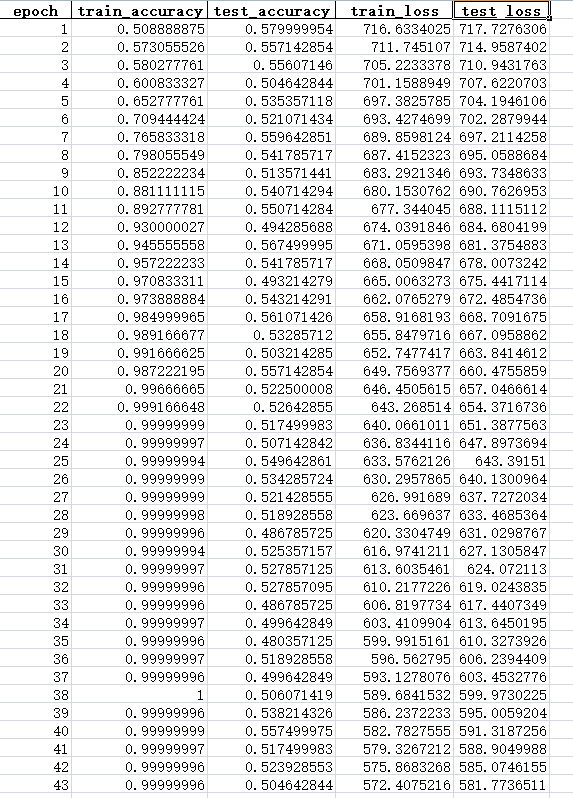

训练准确率很高,测试准确率很低(loss有一直下降)

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

4条回答 默认 最新

- 2023-10-15 21:45便宜牛马的博客 测试集loss不变,准确率不变。以上情况在某种程度上相当于模型不学习了,(只有一组参数,学习完不在学习)epoch,在训练集得到的参数,应用到测试集上。不能等训练集结束再将参数应用到测试集上。在对数据集进行训练...
- 2024-10-21 08:44bug菌¹的博客 你面临的主要问题可能是过拟合、数据不一致性或计算准确率时的逻辑问题。通过增加正则化、确保数据处理一致性、合理选择阈值等方式,可以帮助你提升模型的泛化能力和准确率。希望如上措施及解决方案能够帮到有需要的...
- 2024-06-19 15:31Ai-编码的博客 2.类别不平衡:如果数据集中某些类别的样本数量远远多于其他类别,而模型又没有得到适当的处理(例如使用权重调整、重采样等),那么模型可能会偏向于预测数量最多的类别,导致其他类别的精度很低甚至为0。...
- 2020-10-03 21:49datayx的博客 向AI转型的程序员都关注了这个号????????????机器学习AI算法工程 公众号:datayx最近用keras跑基于resnet50,inception3的一些迁移学习的实验,遇...
- 2019-06-29 17:24彭朝劲的博客 使用小语料集训练,测试精准率还行,当语料集达到2000组时,问题来了,训练精准率很高,但测试精准率非常低。 小语料集与大语料集测试精准率对比: 测试精准率低的让人有点伤心,训练集增多,除了把batch...
- 2020-03-06 17:32CVsaber的博客 自定义标题背景定义关系 背景 在进行一项分类任务训练时,观察到验证集上的...交叉熵损失函数:交叉熵输出的是正确标签的似然对数,和准确率有一定的关系,但是取值范围更大。交叉熵损失公式: 其中y^(i)\widehat{y...
- 2021-01-13 21:36譕訫_的博客 又没有设置防止过拟合的比如学利率一开始设置为1,因为下降太快,那么很有可能在一个epoch旧完全收敛。所以看到的validation数值并不下降,第一个epoch就已经处于谷底了。 最常见的原因:过拟合。主要包括:数据量小...
- 2022-10-08 11:22小六oO的博客 第三层是output layer,它有10个neurons(因为数字无非...经网络训练时准确度突然变得急剧下降,很有可能是你的休息不够睡眠不足导致注意力不集中,近段时间的心情也很影响训练时的准确度,心情烦躁准确度也就会下降。
- 2021-11-15 20:14fwyynl的博客 这个问题很多人在训练自己或者迁移别的网络的时候都会遇到,特别是二分类这样的简单网络,感觉无处着手,都他妈的是对的,就是Loss不动。到底什么原因了?吐槽的网址很多。比如这里,或者这里。若想知道解决办法,请...
- 2024-08-15 14:48绒绒毛毛雨的博客 剪枝实验的基准得是一个微调好的准确率保持较高的模型,按照我之前yolov5的经验来看,这还不简单?选模型+合适的数据集,20轮就OK!我计划使用 ResNet-18模型加上Cifar-10数据集,训练轮次100轮,准确度达到95%我就...
- 没有解决我的问题, 去提问
