
1.如题,我是在keras下用lstm来对本地文件夹中六类垃圾进行图片分类
这是我的部分代码:
(我本地的图片是512 ✖384的,进行resize为200✖160了)
nb_lstm_outputs = 128 #神经元个数
nb_time_steps = 200 #时间序列长度
nb_input_vector = 160 #输入序列
# 读取数据和标签
print("------开始读取数据------")
data = []
labels = []
# 拿到图像数据路径,方便后续读取
imagePaths = sorted(list(utils_paths.list_images('./dataset-resized')))
random.seed(42)
random.shuffle(imagePaths)
# 遍历读取数据
for imagePath in imagePaths:
# 读取图像数据
image = cv2.imread(imagePath)
image = cv2.resize(image, (160,200))
data.append(image)
# 读取标签
label = imagePath.split(os.path.sep)[-2]
labels.append(label)
# 对图像数据做scale操作
data=np.array(data, dtype="float") / 255.0
labels = np.array(labels)
# 数据集切分
(trainX, testX, trainY, testY) = train_test_split(data,labels, test_size=0.25, random_state=42)
# 转换标签为one-hot encoding格式
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
# 设置初始化超参数
EPOCHS = 5
BS = 71
以上就是我的数据预处理操作
下面是我构建的模型:
model = Sequential()
model.add(LSTM(units=nb_lstm_outputs, return_sequences=True,
input_shape=(nb_time_steps, nb_input_vector))) # returns a sequence of vectors of dimension 30
model.add(LSTM(units=nb_lstm_outputs, return_sequences=True)) # returns a sequence of vectors of dimension 30
model.add(LSTM(units=nb_lstm_outputs)) # return a single vector of dimension 30
model.add(Dense(1, activation='softmax'))
model.add(Dense(6, activation='softmax'))
adam=Adam(lr=1e-4)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(trainX, trainY,
epochs = EPOCHS,
batch_size = BS,
verbose = 1,
validation_data = (testX,testY))
后续就是优化和生成loss等的代码了。
然而运行时遇到了以下维度错误:
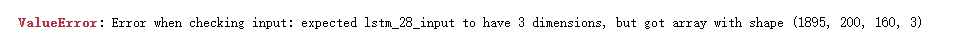
然后我我试着修改不同的尺寸,发现都有上述错误,感觉应该是维度错误,但是不太明白1895是怎么来的?
2.遇到上述维度问题后,不太清楚怎么解决,于是我将代码中读取图片cv2.imread,将图像进行了灰度化:
image = cv2.imread(imagePath,CV2.IMREAD_GRAYSCALE)
调整后,代码可以运行,然而并未按照预先设定的Batchsize进行训练,而是直接以划分的整体比例进行训练,想请问下这是怎么回事?已经输入BS到batch_size的参数了

所以想请问各位大神,怎么解决维度问题,还有就是为什么后面BS传进去不管用啊,有没有清楚怎么一回事的啊?
谢谢各位大神了!!是个小白QAQ谢谢!






