data_train, data_test, label_train, label_test = train_test_split(data_all, label_all, test_size= 0.2, random_state = 1)
data_train, data_val, label_train, label_val = train_test_split(data_train,label_train, test_size = 0.25)
data_train = np.asarray(data_train, np.float32)
data_test = np.asarray(data_test, np.float32)
data_val = np.asarray(data_val, np.float32)
label_train = np.asarray(label_train, np.int32)
label_test = np.asarray(label_test, np.int32)
label_val = np.asarray(label_val, np.int32)
training = model.fit_generator(datagen.flow(data_train, label_train_binary, batch_size=200,shuffle=True), validation_data=(data_val,label_val_binary), samples_per_epoch=len(data_train)*8, nb_epoch=30, verbose=1)
def plot_history(history):
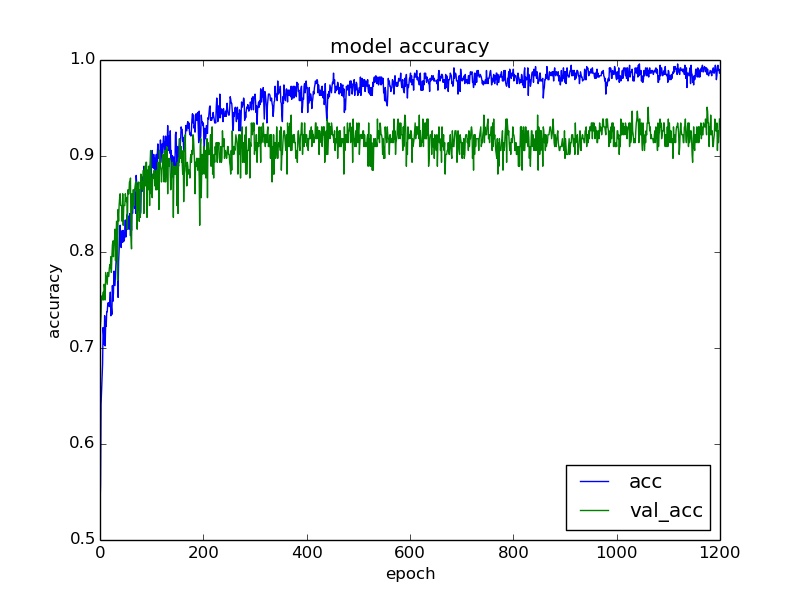
plt.plot(training.history['acc'])
plt.plot(training.history['val_acc'])
plt.title('model accuracy')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.legend(['acc', 'val_acc'], loc='lower right')
plt.show()
plt.plot(training.history['loss'])
plt.plot(training.history['val_loss'])
plt.title('model loss')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['loss', 'val_loss'], loc='lower right')
plt.show()
plot_history(training)