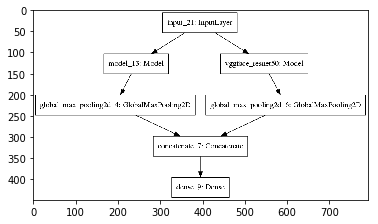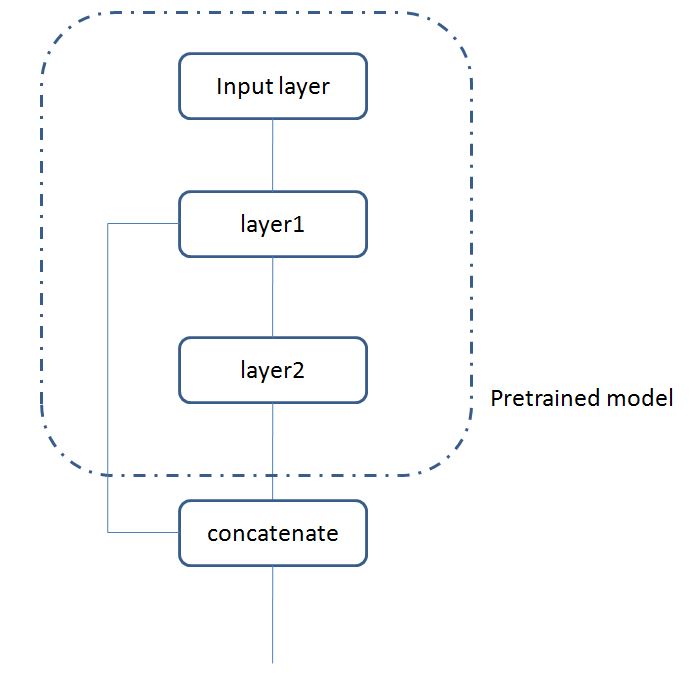
我想从一个预训练的卷积神经网络的不同层中提取特征,然后把这些不同层的特征拼接在一起,实现如上图一样的网络结构,我写的代码如下
base_model = VGGFace(model='resnet50', include_top=False)
model1 = base_model
model2 = base_model
input1 = Input(shape=(197,197,3))
model1_out = model1.layers[-12].output
model1_in = model1.layers[0].output
model1 = Model(model1_in,model1_out)
x1 = model1(input1)
x1 = GlobalMaxPool2D()(x1)
x2 = model2(input1)
x2 = GlobalMaxPool2D()(x2)
out = Concatenate(axis=-1)([x1,x2])
out = Dense(1,activation='sigmoid')(out)
model3 = Model([input1,input2],out)
from keras.utils import plot_model
plot_model(model3,"model3.png")
import matplotlib.pyplot as plt
img = plt.imread('model3.png')
plt.imshow(img)
但模型可视化显示如下,两个网络的权值并不共享。