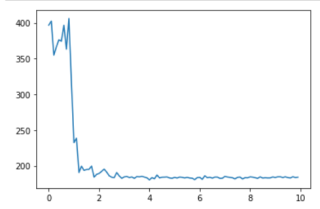
最近开始学习机器学习,在编写简单的二层神经网络的过程中,发现损失函数一直居高不下,然后看了一下损失函数的梯度,发现梯度一直都是零。
我在途中试着改变损失函数,将cross entropy error函数换成mean_squared_error函数;又试着改变激活函数:sigmoid函数,Relu函数,softmax函数都试着用过了;然后又试着改变训练次数,mini_batch的大小,学习率,可惜都无济于事,我希望能够找到问题所在。以下是我的完整代码。希望有大佬能指点一下迷津。
from keras.datasets import mnist
import keras
import numpy as np
from PIL import Image
import matplotlib.pylab as plt
# 显示图形
def img_show(img):
pil_img = Image.fromarray(np.uint8(img))
pil_img.show()
# 2层神经网络的类
class TwoLayerNet:
def __init__(self, input_size, hidden_size, output_size, weight_init_std=0.01):
self.params = {}
self.params['w1'] = weight_init_std * np.random.randn(input_size, hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['w2'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b2'] = np.zeros(output_size)
def predict(self, x): # x=输入
w1, w2 = self.params['w1'], self.params['w2']#权重
b1, b2 = self.params['b1'], self.params['b2']#偏移
a1 = np.dot(x, w1) + b1
z1 = sigmoid(a1)#第一层输出
a2 = np.dot(z1, w2) + b2
z2 = softmax(a2)#第二层输出
return z2
def loss(self, x, t): # x=输入,t=监督数据
y = self.predict(x)
return cross_entropy_error(y, t)
def accuracy(self, x, t):
y = self.predict(x)
y = np.argmax(y, axis=1)
t = np.argmax(t, axis=1)
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
def numerical_gradient(self, x, t):
loss_w = lambda w: self.loss(x, t)#损失函数
grads = {
'w1': numerical_gradient(loss_w, self.params['w1']),
'b1': numerical_gradient(loss_w, self.params['b1']),
'w2': numerical_gradient(loss_w, self.params['w2']),
'b2': numerical_gradient(loss_w, self.params['b2'])
}
return grads
# 梯度函数
def numerical_gradient(f, x):
h = 1e-4
grad = np.zeros_like(x)
for idx in range(x.shape[0]):
tmp_val = x[idx]
x[idx] = tmp_val + h
fxh1 = f(x)
x[idx] = tmp_val - h
fxh2 = f(x)
grad[idx] = (fxh1 - fxh2) / (2 * h)#求梯度
x[idx] = tmp_val#还原x
return grad
# 误差函数cross entropy error
def cross_entropy_error(y, t):
delta = 1e-7
return -np.sum(t * np.log(y + delta))
# softmax函数
def softmax(a):
c = np.max(a)
exp_a = np.exp(a - c) # 防止溢出
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
# sigmoid函数
def sigmoid(a):
out = a.copy()
sel = ((a > 100) & (a < -100))
out = 1 / (1 + np.exp(-a))#sigmoid计算
out[sel] = 1 / (1 + np.exp(-100))#防止指数爆炸
return out
# 验证集转one-hot
(x_train, y_train), (x_test, y_test) = mnist.load_data()
y_train = keras.utils.to_categorical(y_train)
y_test = keras.utils.to_categorical(y_test)
# 数据改为60000*784浮点格式
x_train = x_train.reshape(x_train.shape[0], 784).astype('float')
train_loss_list = []
# 参数初始化
iters_num = 100 # 循环次数
train_size = x_train.shape[0] # 总数据量
batch_size = 32 # 每次取出的数据量
learning_rate = 0.1 # 学习率
network = TwoLayerNet(input_size=784, hidden_size=100, output_size=10) # 创建对象
for i in range(iters_num):
# 获取mini_batch
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
y_batch = y_train[batch_mask]
# 计算梯度
grad = network.numerical_gradient(x_batch, y_batch)
# 更新参数
for key in ('w1', 'b1', 'w2', 'b2'):
network.params[key] = network.params[key] - learning_rate * grad[key]
# 损失量
loss = network.loss(x_batch, y_batch)
train_loss_list.append(loss)
# 损失量图像
x = np.arange(0, iters_num / 10, 0.1)
y = np.array(train_loss_list)
plt.plot(x, y)
plt.show()