loss一直下降 但是val_loss偶尔在波动 val_accuracy也偶尔波动

用bert-bilstm-crf做命名实体识别过拟合应该怎么解决呀?

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

1条回答 默认 最新

 关注不知道你这个问题是否已经解决, 如果还没有解决的话:
关注不知道你这个问题是否已经解决, 如果还没有解决的话:- 这篇文章讲的很详细,请看:BERT-BiLSTM-CRF命名实体识别应用
- 除此之外, 这篇博客: [Python人工智能] 二十六.基于BiLSTM-CRF的医学命名实体识别研究(上)数据预处理中的 1.分割句子对应的标签字典生成 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
命名实体识别需要获取词和边界,通常有许多标记类型,比如词边界、词性、偏旁部首、拼音等特征,接下来我们新建一个文件prepare_data.py。
- prepare_data.py
第一步,将所有文本标记为O。
#encoding:utf-8 import os import pandas as pd from collections import Counter from data_process import split_text from tqdm import tqdm #进度条 pip install tqdm #词性标注 import jieba.posseg as psg train_dir = "train_data" #----------------------------功能:文本预处理--------------------------------- train_dir = "train_data" def process_text(idx, split_method=None): """ 功能: 读取文本并切割,接着打上标记及提取词边界、词性、偏旁部首、拼音等特征 param idx: 文件的名字 不含扩展名 param split_method: 切割文本方法 return """ #定义字典 保存所有字的标记、边界、词性、偏旁部首、拼音等特征 data = {} #-------------------------------------------------------------------- #获取句子 if split_method is None: #未给文本分割函数 -> 读取文件 with open(f'data/{train_dir}/{idx}.txt', encoding='utf8') as f: #f表示文件路径 texts = f.readlines() else: #给出文本分割函数 -> 按函数分割 with open(f'data/{train_dir}/{idx}.txt', encoding='utf8') as f: outfile = f'data/train_data_pro/{idx}_pro.txt' print(outfile) texts = f.read() texts = split_method(texts, outfile) #提取句子 data['word'] = texts print(texts) #-------------------------------------------------------------------- #获取标签 tag_list = ['O' for s in texts for x in s] #双层循环遍历每句话中的汉字 return tag_list #-------------------------------功能:主函数-------------------------------------- if __name__ == '__main__': print(process_text('0',split_method=split_text))输出结果如下图所示:
第二步,读取ANN文件获取每个实体的类型、起始位置和结束位置。

这里采用Pandas读取文件,并且分割符为Tab键,无表头,核心代码如下:
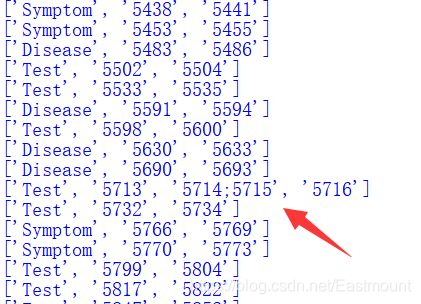
tag = pd.read_csv(f'data/{train_dir}/{idx}.ann', header=None, sep='\t') return tag输出结果如下图所示,我们需要提取下标为1的列。

接着我们提取实体类型、起始位置和结束位置,核心代码如下:
#读取ANN文件获取每个实体的类型、起始位置和结束位置 tag = pd.read_csv(f'data/{train_dir}/{idx}.ann', header=None, sep='\t') #Pandas读取 分隔符为tab键 for i in range(tag.shape[0]): #tag.shape[0]为行数 tag_item = tag.iloc[i][1].split(' ') #每一行的第二列 空格分割 print(tag_item)但会存在某些实体包括两段位置区间的情况,这是因为有空格,这里我们进行简单处理,仅获取实体的起始位置和终止位置。
第三步,实体标记提取。
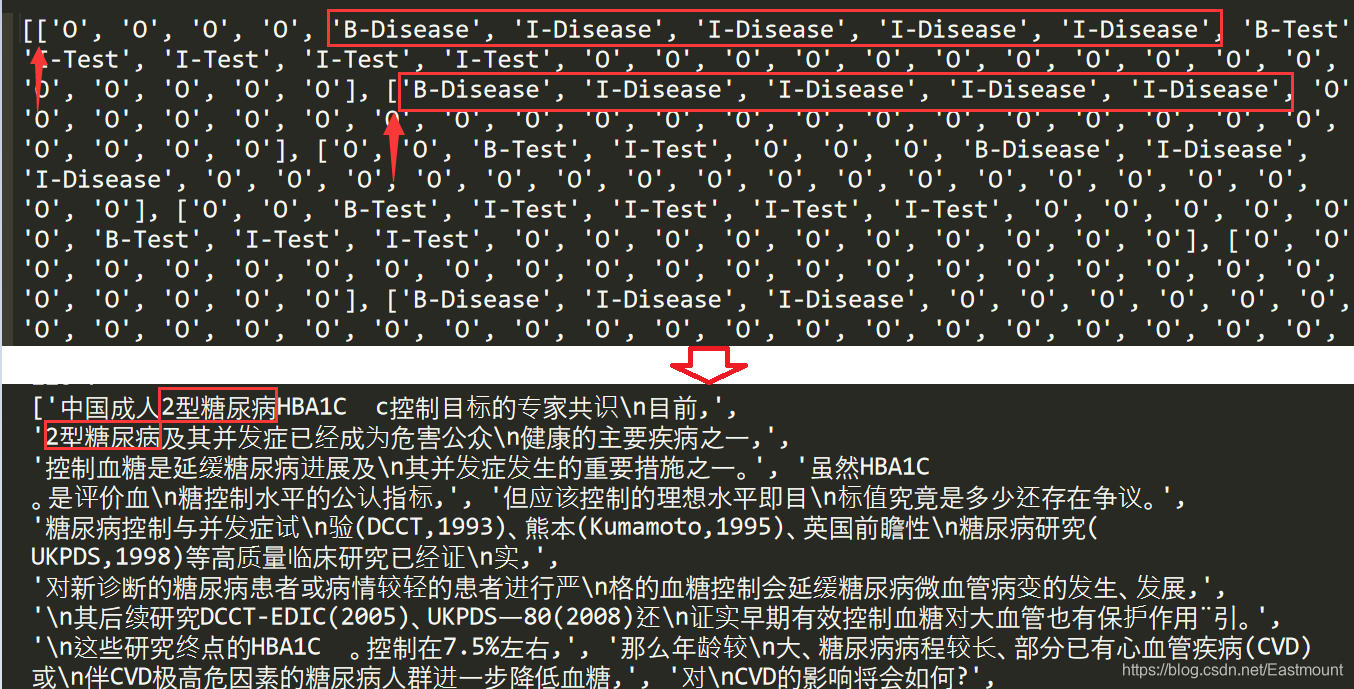
由于之前我们没有对原始TXT文件做任何修改,并且每个TXT和ANN文件的位置是一一对应的,所以接下来我们直接进行词语标记即可。如下图“2型糖尿病”实体位置为30到34。
此时的完整代码如下:
#encoding:utf-8 import os import pandas as pd from collections import Counter from data_process import split_text from tqdm import tqdm #进度条 pip install tqdm #词性标注 import jieba.posseg as psg train_dir = "train_data" #----------------------------功能:文本预处理--------------------------------- train_dir = "train_data" def process_text(idx, split_method=None): """ 功能: 读取文本并切割,接着打上标记及提取词边界、词性、偏旁部首、拼音等特征 param idx: 文件的名字 不含扩展名 param split_method: 切割文本方法 return """ #定义字典 保存所有字的标记、边界、词性、偏旁部首、拼音等特征 data = {} #-------------------------------------------------------------------- #获取句子 #-------------------------------------------------------------------- if split_method is None: #未给文本分割函数 -> 读取文件 with open(f'data/{train_dir}/{idx}.txt', encoding='utf8') as f: #f表示文件路径 texts = f.readlines() else: #给出文本分割函数 -> 按函数分割 with open(f'data/{train_dir}/{idx}.txt', encoding='utf8') as f: outfile = f'data/train_data_pro/{idx}_pro.txt' print(outfile) texts = f.read() texts = split_method(texts, outfile) #提取句子 data['word'] = texts print(texts) #-------------------------------------------------------------------- # 获取标签 #-------------------------------------------------------------------- #初始时将所有汉字标记为O tag_list = ['O' for s in texts for x in s] #双层循环遍历每句话中的汉字 #读取ANN文件获取每个实体的类型、起始位置和结束位置 tag = pd.read_csv(f'data/{train_dir}/{idx}.ann', header=None, sep='\t') #Pandas读取 分隔符为tab键 #0 T1 Disease 1845 1850 1型糖尿病 for i in range(tag.shape[0]): #tag.shape[0]为行数 tag_item = tag.iloc[i][1].split(' ') #每一行的第二列 空格分割 #print(tag_item) #存在某些实体包括两段位置区间 仅获取起始位置和结束位置 cls, start, end = tag_item[0], int(tag_item[1]), int(tag_item[-1]) #print(cls,start,end) #对tag_list进行修改 tag_list[start] = 'B-' + cls for j in range(start+1, end): tag_list[j] = 'I-' + cls return tag_list #-------------------------------功能:主函数-------------------------------------- if __name__ == '__main__': print(process_text('0',split_method=split_text))标记的位置如下图所示,发现它们是对应的。至此,我们成功提取了实体类型和位置。


第四步,将分割后的句子与标签匹配。
它将转换为两个对应的输出:- 分割后的长短句
- 分割后长短句对应的标记数据
#-------------------------------------------------------------------- # 分割后句子匹配标签 #-------------------------------------------------------------------- tags = [] start = 0 end = 0 #遍历文本 for s in texts: length = len(s) end += length tags.append(tag_list[start:end]) start += length return tag_list, tags输出结果如下图所示,我们可以看到第三部分“数据预处理”生成的长短句和我们的标签对应一致。
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^解决 无用评论 打赏举报 分享
- 2024-03-05 14:45Eastmount的博客 这篇文章将继续以中文语料为主,介绍融合Bert的实体识别研究,使用bert4keras和kears包来构建Bert+BiLSTM-CRF模型。然而,该代码最终结果有些问题,目前还在解决中,但现阶段方法先作为在线笔记分享出来。基础性文章...
- 2023-05-27 21:31u013250861的博客 序列标注的命名实体识别众多方法中将CNN、RNN和BERT等深度模型与条件随机场CRF结合已经成为最主流和普遍的方法,在本篇文章中我们仅关注基于CRF的序列标注模型。[机器学习]:早期传统机器学习时代,除了利用人工规则...
- 2025-03-18 11:23西域情歌的博客 本章将简要介绍BERT-IDCNN-BILSTM-CRF模型及其在中文实体识别项目中的应用。自然语言处理(Natural Language Processing,NLP)是计算机科学、人工智能以及语言学领域的一个交叉学科,旨在使计算机能够理解、解释和...
- 2022-05-22 07:13标题中的“Bert + BiLSTM + CRF”是指一种深度学习模型的组合,用于实体命名识别(NER,Named Entity Recognition)。在这个数据集中,你将找到相关资源来理解和实现这样的模型。实体命名识别是自然语言处理(NLP)...
- 2025-05-26 09:04本项目通过结合BERT、BiLSTM和CRF三种技术,构建了一个端到端的命名实体识别系统。BERT作为预训练模型,在大规模文本语料上学习语言的深层语义表示;BiLSTM能够处理序列数据,并通过其双向结构增强模型对上下文的...
- 2025-04-17 21:56zhubeibei168的博客 条件随机场(Conditional Random Field, CRF)是一种用于建模序列数据的统计模型,尤其在自然语言处理中,用于序列标注任务,如命名实体识别(NER)。CRF模型能够处理序列数据中的全局依赖性,这在处理如NER这样的任务时...
- 2025-09-13 02:09色空空色的博客 自然语言处理(NLP)领域中,BERT(Bidirectional Encoder Representations from Transformers)模型作为深度学习的重要突破,通过其独特的双向Transformer编码器结构,显著提升了模型对上下文语义的理解能力。...
- 2024-09-15 08:56明咏耿Helena的博客 该项目位于GitHub上的仓库是chenxiaoyouyou/Bert-BiLSTM-CRF-pytorch,它实现了基于Google预训练BERT模型的双向LSTM-CRF序列标注模型,专为命名实体识别(NER)设计。以下是该仓库的主要目录结构和文件简介: ...
- 2025-07-20 11:02高杉峻的博客 实体识别(Named Entity Recognition,简称NER)是自然语言处理(NLP)的一个基础任务,旨在从文本中识别出具有特定意义的实体,如人名、地名、机构名、日期等。中文实体识别(CNER)特指对中文文本的实体进行识别。...
- 2024-05-21 09:49**基于BiLSTM-CRF网络的中文电子病历命名实体识别** 在医疗信息化领域,中文电子病历(Electronic Medical Records, EMR)的处理是一项关键任务。EMR中蕴含了大量的患者健康信息,如疾病诊断、治疗方案、药物使用等...
- 没有解决我的问题, 去提问


问题事件
 修改了问题
4月3日
修改了问题
4月3日-
创建了问题
4月3日