bert 的tensorflow 版本做 do_predict=TRUE 时 会产生一个文件 test_results.tsv,数据大概是
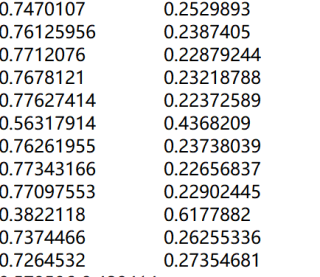
也就是每一个句子都生成了一个概率值,这个概率值具体指的是哪种概率呢?如果我想做双文本的相似度计算,这个概率可以进行使用吗?

bert 的tensorflow 版本做 do_predict=TRUE 时 会产生一个文件 test_results.tsv,数据大概是
也就是每一个句子都生成了一个概率值,这个概率值具体指的是哪种概率呢?如果我想做双文本的相似度计算,这个概率可以进行使用吗?
 分享
分享
这个 test_results.tsv 文件中的数据表示了每个输入样本在每个类别上的概率。在你提供的数据中,有两列,因此我猜测你的模型是一个二分类问题。第一列表示属于类别 0 的概率,第二列表示属于类别 1 的概率。这些概率之和应该等于 1。
关于你的问题:这个概率值能否用于双文本的相似度计算,取决于你的训练数据和标签。如果你的训练数据包含成对的文本,并且标签表示这两个文本之间的相似度(例如,类别 0 表示不相似,类别 1 表示相似),那么这个概率可以用于衡量双文本相似度。
在这种情况下,你可以使用类别 1(即第二列)的概率作为相似度分数。这个概率表示了模型预测两个输入文本相似的程度。较高的概率值表示文本更相似,而较低的概率值表示文本不相似。
分享 系统已结题
4月24日
系统已结题
4月24日 已采纳回答
4月16日
创建了问题
4月16日
已采纳回答
4月16日
创建了问题
4月16日




