楼主最近在学习yolov5,处于刚起步阶段。我们要求使用yolov5的v1.0版本,在使用源代码的train.py的过程中楼主遇到了难以解决的问题,卡了十几个小时没有头绪。楼主用的是2.0.1的pytorch,cuda11.8
报错是这样的:
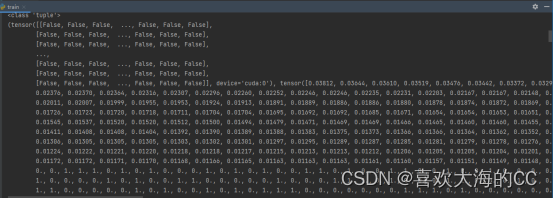
RuntimeError: indices should be either on cpu or on the same device as the indexed tensor (cpu)
对于源码,楼主几乎没有进行任何的修改,只在yolo.py的大约第126行加了
with torch.no_grad()
实际代码块如下:
def _initialize_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency
# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.
m = self.model[-1] # Detect() module
for f, s in zip(m.f, m.stride): # from
mi = self.model[f % m.i]
# mi.to(device=torch.device('cuda:0'))
b = mi.bias.view(m.na, -1) # conv.bias(255) to (3,85)
with torch.no_grad():
b[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)
b[:, 5:] += math.log(0.6 / (m.nc - 0.99)) if cf is None else torch.log(cf / cf.sum()) # cls
mi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)
然后运行train.py时报错:
Traceback (most recent call last):
File "C:\Users\ASUS\Desktop\Study\DeepLearning\New Try\New try2\yolov5-1.0\train.py", line 409, in <module>
train(hyp)
File "C:\Users\ASUS\Desktop\Study\DeepLearning\New Try\New try2\yolov5-1.0\train.py", line 266, in train
loss, loss_items = compute_loss(pred, targets.to(device), model)
File "C:\Users\ASUS\Desktop\Study\DeepLearning\New Try\New try2\yolov5-1.0\utils\utils.py", line 423, in compute_loss
tcls, tbox, indices, anchors = build_targets(p, targets, model) # targets
File "C:\Users\ASUS\Desktop\Study\DeepLearning\New Try\New try2\yolov5-1.0\utils\utils.py", line 508, in build_targets
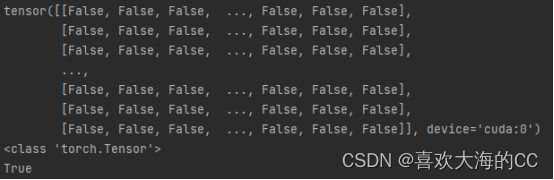
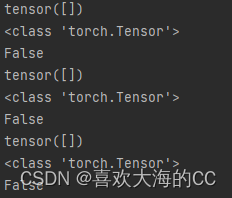
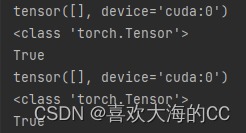
a, t = at[j], t.repeat(na, 1, 1)[j] # filter
RuntimeError: indices should be either on cpu or on the same device as the indexed tensor (cpu)
想请教各位高人怎么办,感谢