使用ConvLSTM预测图像序列总是出现过拟合的问题,数据集是Moving MNIST 移动数据集,前10帧预测后10帧,训练集11000个序列,验证集1000个序列,优化器Adam,学习率0.001,batch_size=10,MSE做损失函数。
已尝试增加normalization、dropout、梯度裁剪、L1与L2正则10e-6、10e-5、10e-4都无法解决过拟合的问题
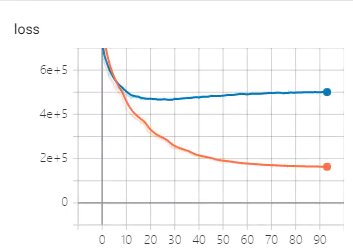
橙色为训练集损失,蓝色为验证集损失,验证集损失训练一段时间开始上升。
请问这种情况该怎样解决?

使用ConvLSTM预测图像序列总是出现过拟合的问题,数据集是Moving MNIST 移动数据集,前10帧预测后10帧,训练集11000个序列,验证集1000个序列,优化器Adam,学习率0.001,batch_size=10,MSE做损失函数。
已尝试增加normalization、dropout、梯度裁剪、L1与L2正则10e-6、10e-5、10e-4都无法解决过拟合的问题
橙色为训练集损失,蓝色为验证集损失,验证集损失训练一段时间开始上升。
请问这种情况该怎样解决?
 分享
分享
没办法,你的训练样本太少。增加训练样本是唯一的办法。
好比吃不饱饭怎么办,不增加饭,采用稀饭掺水,少餐多顿这些办法都治标不治本。
所以你看即便it大厂,也在拼命积攒数据以及人工标注数据,花费大量成本,如果算法能解决,何必如此。
分享


