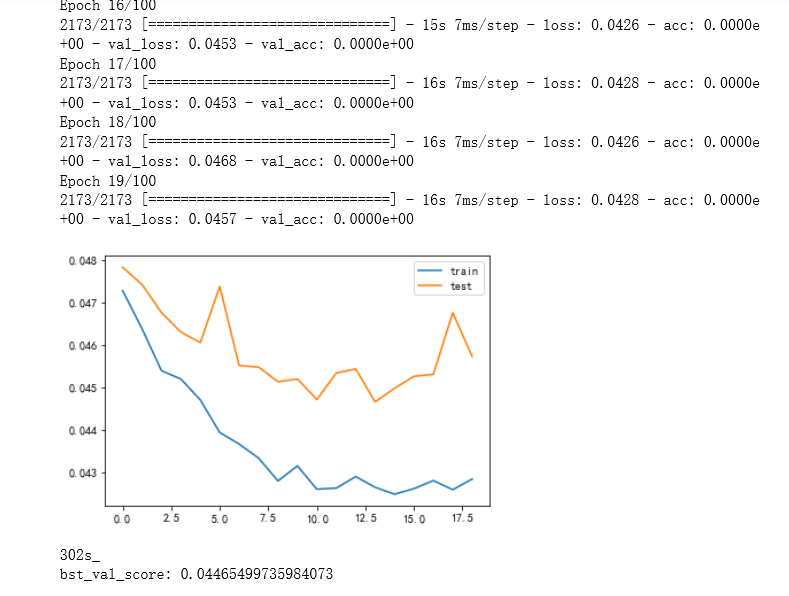
如图,使用lstm做预测loss始终不下降。从一开始就在震荡。想知道原因。

神经网络loss不下降问题

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

2条回答 默认 最新
 threenewbee 2018-11-15 03:05关注
threenewbee 2018-11-15 03:05关注调参没有调好,lstm的unit太大或者太小,用的损失函数不对,如果是分类,用交叉熵,如果是回归,用mse/mae,batch size太大或者太小,数据导入不对,比如维度错了。
用错激活函数,各种激活函数,sigmoid、relu、tanh都试试看,优化器错误或者参数选择不当,比如建议你用adam,如果用sgd,看看学习率lr是不是过大。
数据本身是难以学习的,比如你lstm去学习随机白噪声曲线,肯定学不出来。评论 打赏解决 7无用举报 分享
- 2020-09-18 04:53在使用Pytorch框架进行神经网络的训练过程中,我们可能会遇到loss不下降的问题。这种情况可能会让初学者感到困惑,甚至认为是模型本身存在问题。但实际上,loss不下降的原因可能多种多样,包括但不限于以下几个方面...
- 2022-10-20 19:14小六oO的博客 因为合适的batch size范围和训练数据规模、神经网络层数、单元数都没有显著的关系。经网络训练时准确度突然变得急剧下降,很有可能是你的休息不够睡眠不足导致注意力不集中,近段时间的心情也很影响训练时的准确度,...
- 2022-06-14 09:14yzZ_here的博客 如何解决神经网络训练时loss不下降的问题?当我们训练一个神经网络模型的时候,我们经常会遇到这样的一个头疼的问题,那就是,神经网络模型的loss值不下降,以致我们无法训练,或者无法得到一个效果较好的模型。导致...
- 2020-01-06 09:22xiangyong58的博客 1.learning rate设大了会带来跑飞(loss突然一直很大)的问题 这个是新手最常见的情况——为啥网络跑着跑着看着要收敛了结果突然飞了呢?可能性最大的原因是你用了relu作为激活函数的同时使用了softmax或者带有exp的...
- 2023-05-12 09:44RechelMx的博客 LearningRate设置过大,会带来跑飞的问题。可能性最大的原因是:Relu激活函数与Softmax(带有exp的loss函数)同时使用。如果数据太少尽量缩小模型复杂度。...为什么同时使用两种函数产生loss跑飞问题?
- 2022-06-28 22:27张先生非常坏的博客 Loss函数陷入鞍点\局部最优
- 2025-03-18 11:02黄昏ivi的博客 MSE 是回归任务中最基础的损失函数,通过最小化预测值与真实值的平方误差驱动模型优化。...:MSE 是光滑的凸函数,梯度容易计算,适合梯度下降等优化算法。:在某些场景下(如需要模型重视大误差的任务),这是优点。
- 2020-11-20 15:04inCorning的博客 当我们训练一个神经网络模型的时候,我们经常会遇到这样的一个头疼的问题,那就是,神经网络模型的loss值不下降,以致我们无法训练,或者无法得到一个效果较好的模型。导致训练时loss不下降的原因有很多,而且,更...
- 2024-09-06 20:30依夏c的博客 其原因是:带momentum的方法训练,可看作在参数值和momentum组成的二元组上,每步乘一个矩阵,然后加一个噪音。不发散,要求这个矩阵的...如图,对于val_loss和train_loss在训练初期出现上升,而后逐渐下降的情况是。
- 2025-06-12 02:54AI大模型应用工坊的博客 迁移学习在AI人工智能领域具有重要的意义,其目的在于解决传统机器学习中数据稀缺、训练成本高以及模型泛化能力不足等问题。通过将在一个或多个源任务上学习到的知识迁移到目标任务中,能够显著提高目标任务的学习...
- 没有解决我的问题, 去提问

