

毕业论文,物流方向的,想做一个LSTM的预测,在b站上找了个教程,训练出的结果绘图符合预期,但是需要预测的目标数据范围从22.2-23.6变成了0-120。
因为之前从未接触过python和机器学习,所以就把全部代码放出来:
这里得出的RMSE也不符合预期,找正常数据来说跨度不可能这么大
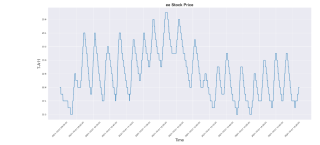
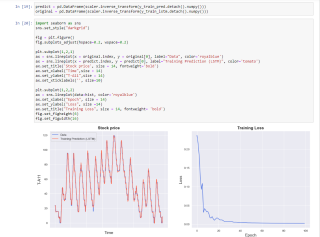
在这里的结果中,y轴数据范围变成了0-120,但是图形符合预期
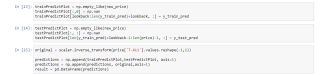
在最后的汇总图里面,y轴数据仍然和原来的不一样,图形仍符合预期
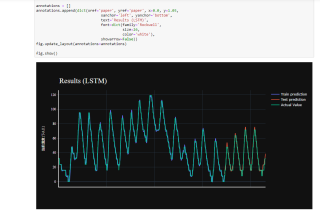
训练过程和代码如上,使用的是jupyter,求知道怎么让训练结果的y轴和实际数据相同,且RMSE符合预期,谢谢各位。
jupyter上复制下来的代码在这下面:
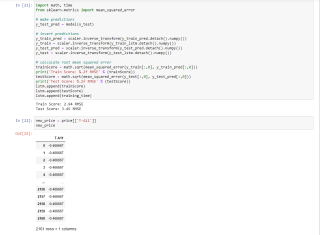
# In[1]:
import numpy as np
import pandas as pd
# In[2]:
filepath = 'C:/Users/本子怪/Desktop/论文/实验数据/分析用数据/DATA10.01.csv'
data = pd.read_csv(filepath)
data = data.sort_values('Time')
data.head()
# In[3]:
data.shape
# In[4]:
import matplotlib.pyplot as plt
import seaborn as sns
sns. set_style("darkgrid")
plt. figure(figsize = (21, 9))
plt. plot(data[['T-A11']])
plt. xticks (range(0,data.shape[0],150), data['Time'].loc[::150],rotation=45)
plt. title("ee Stock Price",fontsize=18, fontweight='bold')
plt. xlabel('Time',fontsize=18)
plt. ylabel('T-A11',fontsize=18)
plt. show()
# In[5]:
price = data[['T-A11','Twr','PreCool','Tpre','Cmen','Aopen']]
price
# In[6]:
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(-1,1))
price['T-A11'] = scaler.fit_transform(price['T-A11'].values.reshape(-1,1))
# In[7]:
price['Twr'] = scaler.fit_transform(price['Twr'].values.reshape(-1,1))
# In[8]:
price['PreCool'] = scaler.fit_transform(price['PreCool'].values.reshape(-1,1))
# In[9]:
price['Tpre'] = scaler.fit_transform(price['Tpre'].values.reshape(-1,1))
# In[10]:
price['Cmen'] = scaler.fit_transform(price['Cmen'].values.reshape(-1,1))
# In[11]:
price['Aopen'] = scaler.fit_transform(price['Aopen'].values.reshape(-1,1))
price
# In[12]:
def split_data(stock, lookback):
data_raw = stock.to_numpy()
data = []
# you can free play (seqlength)
for index in range(len(data_raw) - lookback):
data.append(data_raw[index: index + lookback])
data = np.array(data);
test_set_size = int(np.round(0.2 * data.shape[0]))
train_set_size = data.shape[0] - (test_set_size)
x_train = data[:train_set_size,:-1,:]
y_train = data[:train_set_size,-1,0:1]
x_test = data[train_set_size:,:-1,:]
y_test = data[train_set_size:,-1,0:1]
return [x_train, y_train, x_test, y_test]
# In[13]:
lookback = 20
x_train, y_train, x_test, y_test = split_data(price, lookback)
print('x_train.shape = ',x_train.shape)
print('y_train.shape = ',y_train.shape)
print('x_test.shape = ',x_test.shape)
print('y_test.shape = ',y_test.shape)
# In[14]:
import torch
import torch.nn as nn
x_train = torch.from_numpy (x_train).type(torch.Tensor)
x_test = torch.from_numpy(x_test).type(torch.Tensor)
y_train_lstm = torch.from_numpy(y_train).type(torch.Tensor)
y_test_lstm = torch.from_numpy(y_test).type(torch.Tensor)
y_train_gru = torch.from_numpy(y_train).type(torch.Tensor)
y_test_gru = torch.from_numpy(y_test).type(torch.Tensor)
# In[15]:
input_dim = 6
hidden_dim = 32
num_layers = 2
output_dim = 1
num_epochs = 100
# In[16]:
class LSTM(nn.Module):
def __init__(self, input_dim, hidden_dim, num_layers, output_dim):
super(LSTM, self). __init__()
self.hidden_dim = hidden_dim
self.num_layers = num_layers
self.lstm = nn.LSTM(input_dim, hidden_dim, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).requires_grad_()
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).requires_grad_()
out, (hn,cn)= self.lstm(x, (h0.detach(), c0.detach()))
out = self.fc(out[:,-1, :])
return out
# In[17]:
model = LSTM(input_dim=input_dim, hidden_dim = hidden_dim, num_layers = num_layers, output_dim = output_dim)
criterion = torch.nn.MSELoss()
optimiser = torch.optim.Adam(model.parameters(),lr=0.01)
# In[18]:
import time
hist = np.zeros(num_epochs)
start_time = time.time()
lstm = []
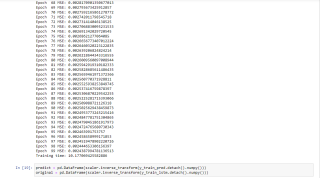
for t in range(num_epochs):
y_train_pred = model(x_train)
loss = criterion(y_train_pred, y_train_lstm)
print("Epoch ", t,"MSE:", loss.item())
hist[t] = loss.item()
optimiser.zero_grad()
loss.backward()
optimiser.step()
training_time = time.time()-start_time
print("Training time: {}".format(training_time))
# In[19]:
predict = pd.DataFrame(scaler.inverse_transform(y_train_pred.detach().numpy()))
original = pd.DataFrame(scaler.inverse_transform(y_train_lstm.detach().numpy()))
# In[20]:
import seaborn as sns
sns.set_style("darkgrid")
fig = plt.figure()
fig.subplots_adjust(hspace=0.2, wspace=0.2)
plt.subplot(1,2,1)
ax = sns.lineplot(x = original.index, y = original[0], label="Data", color='royalblue')
ax = sns.lineplot(x = predict.index, y = predict[0], label="Training Prediction (LSTM)", color='tomato')
ax.set_title('Stock price', size = 14, fontweight='bold')
ax.set_xlabel("Time",size = 14)
ax.set_ylabel("T-A11",size = 14)
ax.set_xticklabels('', size=10)
#手动更改标签以及刻度
#ax.set_yticklabels([22.2,22.4,22.6,22.8,23.0,23.2,23.4,23.6])
plt.subplot(1,2,2)
ax = sns.lineplot(data=hist, color='royalblue')
ax.set_xlabel("Epoch", size = 14)
ax.set_ylabel("Loss", size =14)
ax.set_title("Training Loss", size = 14, fontweight= 'bold')
fig.set_figheight(6)
fig.set_figwidth(16)
# In[21]:
import math, time
from sklearn.metrics import mean_squared_error
# make predictions
y_test_pred = model(x_test)
# invert predictions
y_train_pred = scaler.inverse_transform(y_train_pred.detach().numpy())
y_train = scaler.inverse_transform(y_train_lstm.detach().numpy())
y_test_pred = scaler.inverse_transform(y_test_pred.detach().numpy())
y_test = scaler.inverse_transform(y_test_lstm.detach().numpy())
# calculate root mean squared error
trainScore = math.sqrt(mean_squared_error(y_train[:,0], y_train_pred[:,0]))
print('Train Score: %.2f RMSE' % (trainScore))
testScore = math.sqrt(mean_squared_error(y_test[:,0], y_test_pred[:,0]))
print('Test Score: %.2f RMSE' % (testScore))
lstm.append(trainScore)
lstm.append(testScore)
lstm.append(training_time)
# In[22]:
new_price = price[['T-A11']]
new_price
# In[23]:
trainPredictPlot = np.empty_like(new_price)
trainPredictPlot[:,0] = np.nan
trainPredictPlot[lookback:len(y_train_pred)+lookback, :] = y_train_pred
# In[24]:
testPredictPlot = np.empty_like(new_price)
testPredictPlot[:, :] = np.nan
testPredictPlot[len(y_train_pred)+lookback-1:len(price)-1, :] = y_test_pred
# In[25]:
original = scaler.inverse_transform(price['T-A11'].values.reshape(-1,1))
predictions = np.append(trainPredictPlot,testPredictPlot, axis=1)
predictions = np.append(predictions, original,axis=1)
result = pd.DataFrame(predictions)
# In[26]:
import plotly.express as px
import plotly.graph_objects as go
fig = go.Figure()
fig.add_trace(go.Scatter(go.Scatter(x=result.index, y=result[0],
mode='lines',
name='Train prediction')))
fig.add_trace(go.Scatter(x=result.index, y=result[1],
mode='lines',
name='Test prediction'))
fig.add_trace(go.Scatter(go.Scatter(x=result.index, y=result[2],
mode='lines',
name='Actual Value')))
fig.update_layout(
xaxis=dict(
showline=True,
showgrid=True,
showticklabels=False,
linecolor='white',
linewidth=2
),
yaxis=dict(
title_text='当前温度 (T-A11)',
titlefont=dict(
family='Rockwell',
size=12,
color='white',
),
showline=True,
showgrid=True,
showticklabels=True,
linecolor='white',
linewidth=2,
ticks='outside',
tickfont=dict(
family='Rockwell',
size=12,
color='white',
),
),
showlegend=True,
template ='plotly_dark'
)
annotations = []
annotations.append(dict(xref='paper', yref='paper', x=0.0, y=1.05,
xanchor='left', yanchor='bottom',
text='Results (LSTM)',
font=dict(family='Rockwell',
size=26,
color='white'),
showarrow=False))
fig.update_layout(annotations=annotations)
fig.show()






